Sequence Parallelism序列并行(一)
原始论文 Reducing Activation Recomputation in Large Transformer Models
序列并行
序列并行是在张量并行的基础上进行的进一步深度优化,旨在减少“中间值”带来的显存占用(“中间值”是反向传播所必需的。如果不保存这些中间值,在反向传播过程中就必须重新执行前向计算来生成它们,这会显著增加训练的时间开销)。^1
关于 Transformer 各层的显存占用分析,请参考我的文章:
关于张量并行,请参考我的文章:
“中间值”显存占用分析
符号约定
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| $a$ | number of attention heads | $p$ | pipeline parallel size |
| $b$ | microbatch size | $s$ | sequence length |
| $h$ | hidden dimension size | $t$ | tensor parallel size |
| $L$ | number of transformer layers | $v$ | vocabulary size |
未采用并行机制的 Transformer 架构
架构如下图,我们主要关注图中灰色部分的 Transformer Layer,因为它会重复 $L$ 层,占显存开销的大头。
![]()
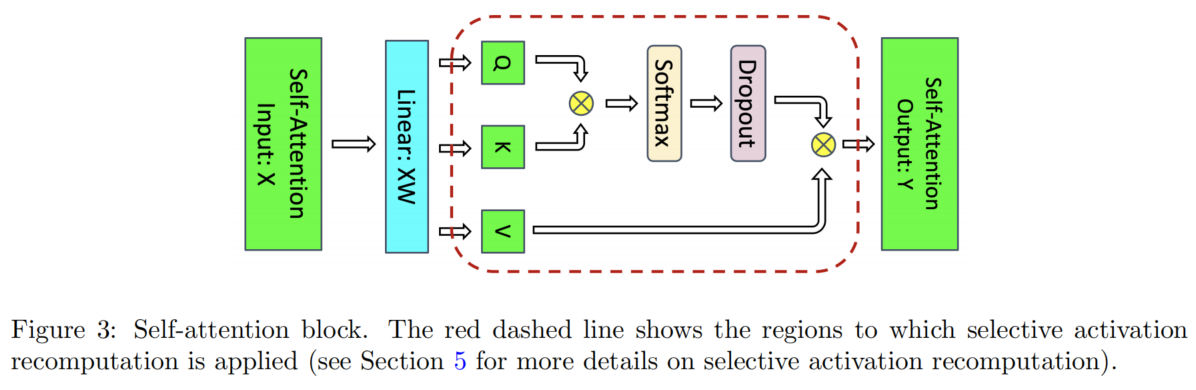
假设采用 FP16 / BF16 精度,下面我们对中间值的显存占用进行拆解分析。
Attention Block
| 中间值 | 大小 |
|---|---|
| Q/K/V projection 共享输入 | $2sbh$ |
| $QK^\top$ 需要存 Q 和 K | $4sbh$ |
| Softmax 输出 | $2as^2b$ |
| Softmax dropout mask | $as^2b$ |
| Attention over V: dropout 输出 | $2as^2b$ |
| V | $2sbh$ |
| Output linear projection 输入 | $2sbh$ |
| Attention dropout mask | $sbh$ |
中间值合计占用:
MLP Block
| 项 | 大小 |
|---|---|
| 第一个 linear 输入 | $2sbh$ |
| 第二个 linear 输入 | $8sbh$ |
| GeLU 输入 | $8sbh$ |
| MLP dropout mask | $sbh$ |
中间值合计占用:
LayerNorm
两个 LayerNorm,每个存输入 $2sbh$,所以
合计
采用张量并行机制的 Transformer 架构
采用张量并行机制的 Transformer 架构如下图:
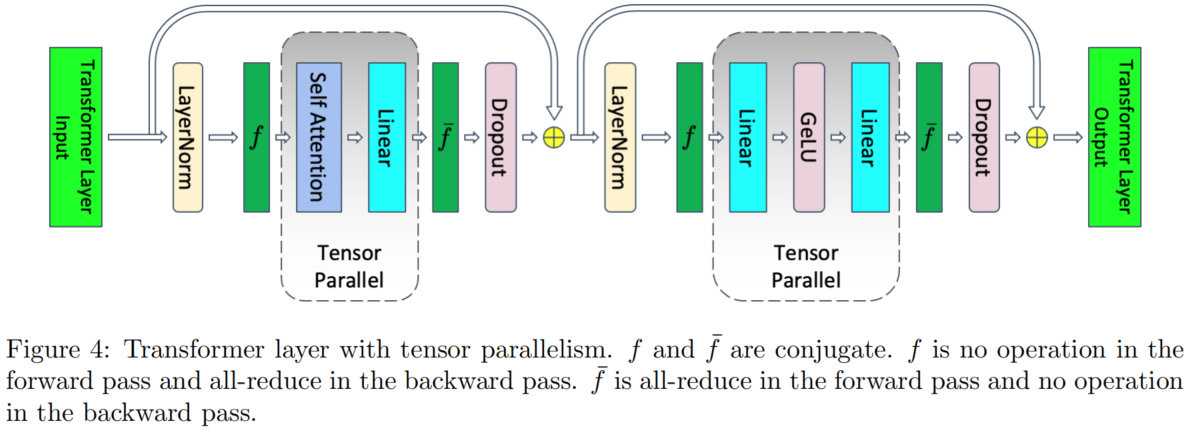
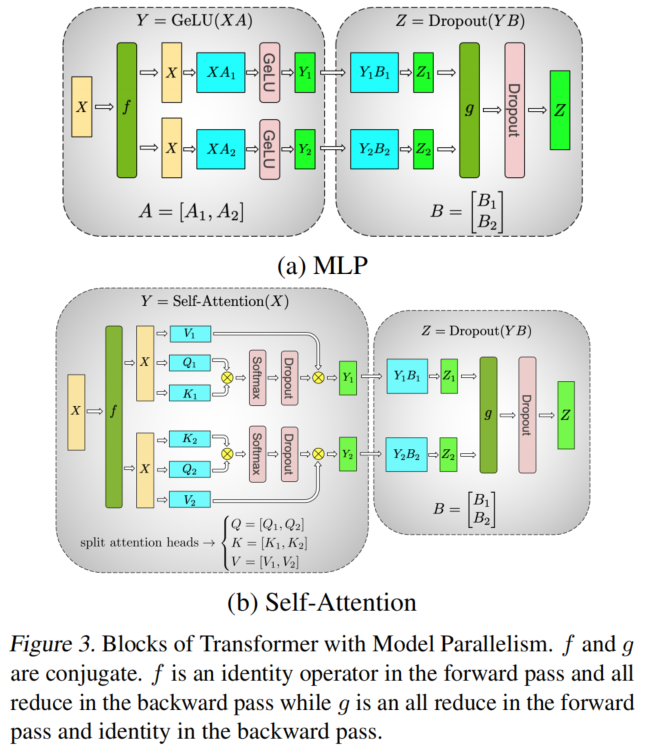
引入张量并行度为 $t$,进行中间值占用的显存分析:
Attention Block
| 项 | 原大小 | Tensor Parallel 后 |
|---|---|---|
| Q/K/V projection 共享输入 | $2sbh$ | 不切,仍是 $2sbh$ |
| $QK^\top$ 需要存 Q 和 K | $4sbh$ | 切,变成 $\frac{4sbh}{t}$ |
| Softmax 输出 | $2as^2b$ | 切,变成 $\frac{2as^2b}{t}$ |
| Softmax dropout mask | $as^2b$ | 切,变成 $\frac{as^2b}{t}$ |
| Attention over V: dropout 输出 | $2as^2b$ | 切,变成 $\frac{2as^2b}{t}$ |
| $V$ | $2sbh$ | 切,变成 $\frac{2sbh}{t}$ |
| Output linear projection 输入 | $2sbh$ | 切,变成 $\frac{2sbh}{t}$ |
| Attention dropout mask | $sbh$ | 不切,仍是 $sbh$ |
因此 attention 部分变成:
MLP Block
| 项 | 原大小 | Tensor Parallel 后 |
|---|---|---|
| 第一个 linear 输入 | $2sbh$ | 不切,仍是 $2sbh$ |
| 第二个 linear 输入 | $8sbh$ | 切,变成 $\frac{8sbh}{t}$ |
| GeLU 输入 | $8sbh$ | 切,变成 $\frac{8sbh}{t}$ |
| MLP dropout mask | $sbh$ | 不切,仍是 $sbh$ |
因此 MLP 部分变成:
LayerNorm
张量并行未应用到 LayerNorm,故存储的中间值不变,即两个 LayerNorm,每个存输入 $2sbh$:
合计
采用序列并行 + 张量并行的 Transformer 架构
序列并行进一步将公式中的 $10sbh$ 项并行化。
其具体实现方式如下图。需要说明的是,序列并行并非独立运作,而是与张量并行协同工作的。
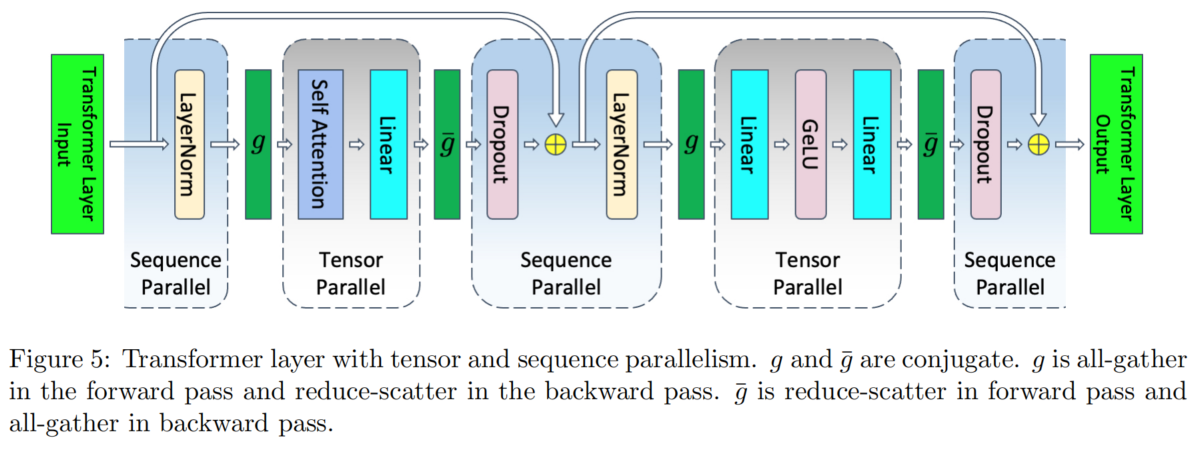
我们以已经张量并行的 MLP 块和它前面的 LayerNorm 和 它后面的 Dropout 层为例,如下图所示,其中有两个 GPU:
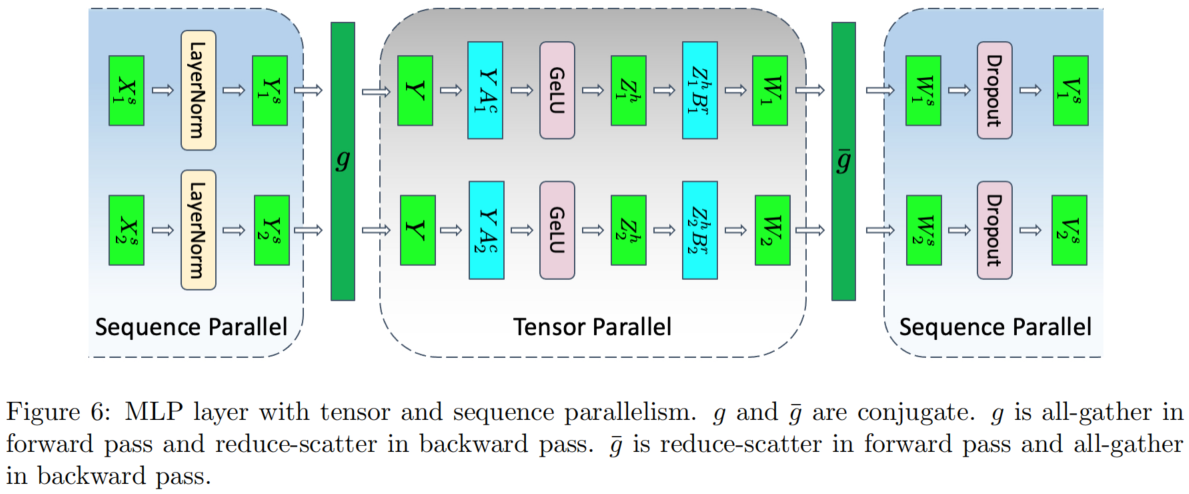
此处的一般维度设定如下:
- 输入:$X: s \times b \times h$
- 投影矩阵:$A: [h, 4h]$,$B: [4h, h]$
符号说明:
- $Y_1^s$:将 $Y$ 按 $s$ 方向切分成两份,其中第一份(存放在第一个 GPU 上)记为 $Y_1^s$。
- $A_1^c$:将 $A$ 按列方向切分成两份,其中第一份(存放在第一个 GPU 上)记为 $A_1^c$。
- $B_1^r$:将 $B$ 按行方向切分成两份,其中第一份(存放在第一个 GPU 上)记为 $B_1^r$。
这些符号不必刻意记忆。关键是,序列并行的可行性在于:LayerNorm 和 Dropout 按 $s$ 方向(即序列维度)切分后,并不会影响其计算结果。中间涉及的其他切分操作,只是为了配合 LayerNorm 和 Dropout 按 $s$ 维度切分而做的必要调整。按照维度动手推一遍即可理解。
为了完成整个操作,我们需要设定通信算子 $g$ 和 $\overline{g}$。其中:
- $g$: forward 时为 all-gather; 根据通信算子和伴随通信算子[1]的性质,快速得到 backward 时为 reduce-scatter
- $\overline{g}$: forward 时为 reduce-scatter; 根据通信算子和伴随通信算子的性质,快速得到 backward 时为 all-gather
因此,对于图 5 所示的“张量并行 + 序列并行”架构,每个 Transformer 层在每轮前向与反向传播中,共需要执行 4 次 all-gather 和 4 次 reduce-scatter。
而在图 4 的纯张量并行架构中,每层每轮前向与反向传播总共需要 4 次 all-reduce。
乍看之下,通信操作似乎变多了,但由于一次 all-reduce 的通信量相当于一次 all-gather 与一次 reduce-scatter 之和[2],因此总的通信量实际上并未增加。
此外,还需注意一点:在 MLP 块中,完整的 $Y$ 仍然在每个 GPU 上都有备份。为解决这一问题,可将 $Y$ 也按 $s$ 维度切分为 $Y_1$、$Y_2$。不过,在计算 $\text{GeLU}$ 之前,仍需执行一次 all-gather 操作。本文的做法是将这次 all-gather 与反向传播中计算 $Y$ 的梯度(该梯度的计算仅需 $A$ 即可完成)进行重叠,从而降低通信延迟[3]。
Attention 块与 MLP 块类似,这里就不赘述了,论文中其实也只是以 MLP 块举例。
合计
采用“序列并行+张量并行”后,Transformer 架构中中间值的显存占用变为:
$$
后记采用激活重计算
上述的显存占用公式中,其实最后一项:
$$\frac{sbh}{t}(5\frac{as}{h})$$
占用的显存显著大于前面的常数项。为了量化这一点,让我们考虑一下 GPT-3 和 MT-NLG 模型。对于 GPT-3,$a = 96$,$s = 2048$,$h = 12288$,因此 $\frac{5as}{h} = 80$。对于 MT-NLG,$a = 128$,$s = 2048$,$h = 20480$,所以 $\frac{5as}{h} = 64$。
所以,可以将 $\frac{sbh}{t}(5\frac{as}{h})$ 进行激活重计算[4],从而达到显存开销和训练时间开销的一种权衡。
评论