互联网络(二):伴随通信算子
什么是伴随通信算子
在神经网络的自动微分过程中,通信算子有一个特别重要的规律:
如果前向传播过程中使用通信算子 ,存在:
根据链式法则,反向传播时:
现在看输出向量的每一个分量 对输入向量的每一个分量 的偏导数:
将这个结果填入雅可比矩阵 中,它的第 行、第 列恰好就是 。所以矩阵的每个位置都对应矩阵 的元素:
因此可以简记为:
这正好与反向传播公式 衔接上了,其中的转置正是来源于这个雅可比矩阵 。
其中 ,
其中 就是 的伴随通信算子。
常用通信算子及其伴随算子汇总如下[2]:
| 前向通信算子 | 伴随/反向通信算子 | 说明与简单举例 |
|---|---|---|
AllReduce |
AllReduce |
所有 rank 的张量先求和/平均,再把结果发给所有 rank。反向仍是全局规约。例:数据并行中,各 GPU 计算本地梯度后用 AllReduce 得到全局平均梯度。 |
Broadcast |
Reduce |
前向是一到多,反向是多到一。例:rank 0 将参数 W 广播给所有 GPU;反向时各 GPU 上关于 W 的梯度需要 Reduce 回 rank 0。 |
Reduce |
Broadcast |
前向是多到一,反向是一到多。例:多个 GPU 的 loss 被 Reduce 到 rank 0;反向时 rank 0 上的梯度信号需要 Broadcast 回其他 rank。 |
Scatter |
Gather |
前向是把一个完整张量切分后分发到多个 rank;反向要把各分片梯度收集回来。例:rank 0 将输入 batch 切成多份 Scatter 给各 GPU;反向时各 GPU 的输入梯度用 Gather 收回。 |
Gather |
Scatter |
前向是多个 rank 的数据收集到一个 rank;反向要把梯度切开再分发回去。例:评估时各 GPU 的预测结果 Gather 到 rank 0;若参与反向,rank 0 上的梯度需 Scatter 回各 GPU。 |
AllGather |
ReduceScatter |
前向是各 rank 的分片被收集成完整张量,并且每个 rank 都拿到完整结果;反向时完整梯度需要规约后再按分片分发。例:FSDP 中前向前用 AllGather 收集完整参数,反向后用 ReduceScatter 得到各自的梯度分片。 |
ReduceScatter |
AllGather |
前向是先对所有 rank 的张量规约,再把结果切分给各 rank;反向需要把分片梯度重新收集成完整梯度。例:ZeRO/FSDP 中用 ReduceScatter 同步并切分梯度;反向对应路径需要 AllGather 汇集分片梯度。 |
AllToAll |
AllToAll |
前向是所有 rank 之间互相交换分片;反向通常也是一次相反方向或相反维度的 AllToAll。例:MoE 中先用 AllToAll 把 token 分发给不同专家,反向时再用 AllToAll 把梯度送回原 token 所在 rank。 |
Send |
Recv |
前向点对点发送数据,反向对应接收梯度。例:流水线并行中 stage 0 前向 Send 激活到 stage 1;反向时 stage 0 需要 Recv 来自 stage 1 的激活梯度。 |
Recv |
Send |
前向点对点接收数据,反向对应发送梯度。例:流水线并行中 stage 1 前向 Recv stage 0 的激活;反向时 stage 1 需要 Send 激活梯度回 stage 0。 |
我们需要计算 的梯度。根据链式法则:
关键在于全 1 矩阵是对称的:
因为矩阵中每个元素都是 1,转置后仍然每个元素都是 1,矩阵不变。 因此:
也就是说,反向计算与正向计算的矩阵完全相同:
每台设备 都收到所有上游梯度 的总和。
伴随通信算子的作用
当前向传播使用通信算子 时,反向传播就必须使用伴随通信算子 。
然而,这似乎有一个例外,如下图的 tensor parallelism 架构:
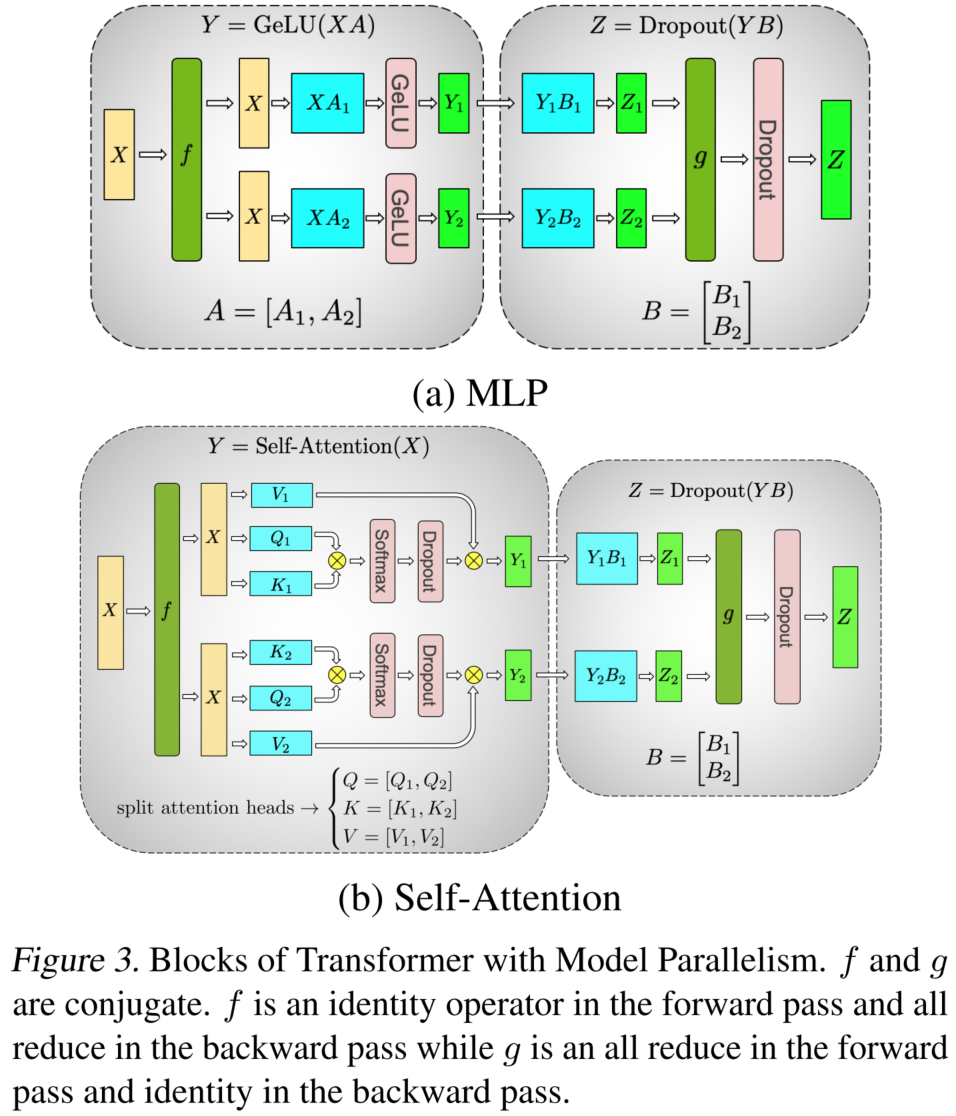
根据论文中的说法,有:
- 正向传播使用 all-reduce,反向传播使用 identity。
- 正向传播使用 identity,反向传播使用 all-reduce。
然而,以 举例,在它反向传播过程中使用的所谓 "identity",其实就是 all-reduce:即每台设备 都收到所有上游梯度 的总和。只是上游梯度 已经汇总到了一台设备上,所以表现为所谓的 "identity"。
所以,在 Megatron-LM 论文中的表述,并不算是纯粹通信算子的描述。
评论