软件调优(七):选择合适的张量数据类型
最初,神经网络训练使用的张量类型都是 fp32,但速度慢、占用显存大。此后,NVIDIA 提出了混合精度训练,研究人员结合使用 fp16 和 fp32 两种浮点精度格式,这一创新极大地提升了模型训练速度。
混合精度训练(Mixed Precision Training)
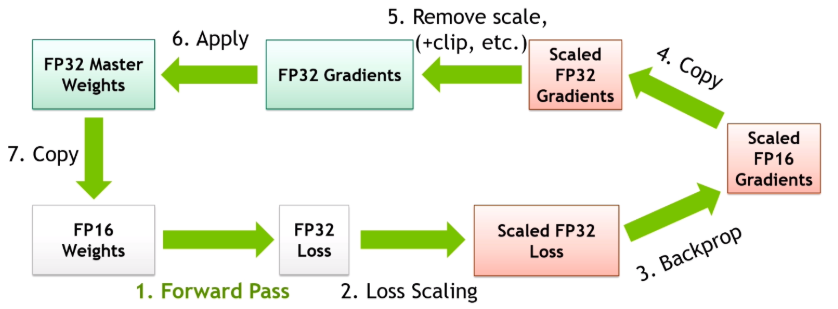
图片中的混合精度训练流程可以概括为以下步骤:
Step 1:Forward Pass
使用 FP16 weights 进行前向传播。虽然权重和激活可能是 FP16,但 loss 通常会保留为 FP32。
Step 2:Loss Scaling
对 loss 进行放大。原因是 FP16 能表示的最小数有限,很多小梯度可能会下溢成 0。通过把 loss 放大,反向传播得到的梯度也会整体放大,从而避免小梯度丢失。
反向传播中的梯度和 loss 是线性相关的[1]。如果我们把 loss 放大一个倍数,那么反向传播得到的梯度也会被放大同样的倍数。这个值就更容易被 FP16 表示,不容易下溢成 0。
相比逐个放大所有参数的梯度,直接放大 loss 更加高效。
Step 3:Backprop
用放大后的 loss 进行反向传播,得到被放大的 FP16 梯度。
Step 4:Copy
将 FP16 梯度复制或转换为 FP32,从而避免在低精度中做梯度累加和参数更新。
Step 5:Remove Scale
把梯度缩放还原。这一步会除以 loss scale,同时可能进行:
- 检查 Inf / NaN:如果 scale 太大,梯度可能被放大到超过 FP16 最大范围,导致 Inf / NaN。此时该梯度就不能执行 optimizer step,否则参数会被污染
- 决定是否跳过 optimizer step:如果使用了梯度累积(GAS),必须等当前梯度累积周期内所有 micro-batch 的反向传播都完成后,才能执行一次梯度更新
- 动态调整 scale:动态调整 scale,本质上就是自动寻找一个“尽量大但又不溢出”的缩放因子。目标是,scale 足够大,避免下溢;如果检测到上溢,则立即减少 scale
- 在 remove scale 后做 gradient clipping:梯度裁剪通过限制梯度的最大范数,防止反向传播中梯度指数爆炸导致训练崩溃
注意,必须首先进行 Remove Scale,否则处理的都是放大 scale 倍的梯度,结果会严重错误。
Step 6:Apply
使用 FP32 gradients 更新 FP32 master weight。这是混合精度训练的关键:虽然计算可以用 FP16,但真正的主权重用 FP32 保存,优化器更新也作用在 FP32 master weights 上。
Step 7:Copy
把更新后的 FP32 master weights 转回 FP16,用于下一轮前向/反向传播。
低精度训练中的累加通常优先使用 FP32
在低精度训练中,许多累加、规约和统计操作通常会使用 FP32 完成,以减小舍入误差并提高数值稳定性。否则,在长链路累加或对精度敏感的计算中,误差可能会明显积累。
类似 LayerNorm、Softmax 以及均值/方差统计这类对数值精度较敏感的操作,通常会在 FP32 精度下完成关键计算,之后再将结果转换回输入所使用的低精度格式。
下面是一些典型例子:
1. 规约集合通信
- 对于 FP16 和 BF16,集合通信中的规约通常可以直接使用低精度数据类型,以减少通信开销。
- 但从数值稳定性的角度看,若条件允许,使用 FP32 进行累加或规约通常更稳妥。
- 其中,FP16 常需要配合 loss scaling 以降低梯度下溢风险;BF16 一般不那么依赖 loss scaling,但这并不意味着它只能在 FP32 下进行规约。
2. 梯度累加
- 对于 FP16 和 BF16,梯度累加通常都建议使用 FP32,以减小多次累加带来的精度损失。
- 尤其在梯度累积步数较多、梯度范围变化较大时,使用 FP32 累加器会更加稳定。
3. 优化器更新
- 当一个较小的梯度更新量加到一个较大的参数值上时,如果直接在低精度下更新,该更新量可能会因为精度不足而被舍入掉。
- 因此,混合精度训练中通常会维护 FP32 主权重,并使用 FP32 优化器状态 来执行优化器更新,以保证更新的有效性和稳定性。
ml_dtypes 库
ml_dtypes 库 介绍并实现了机器学习中常用的多种低精度数据类型。其整体实现可以概括为:
-
在底层使用 C++ 实现相关数值类型及其运算逻辑,其中部分功能依赖高性能 C++ 数学库 Eigen。
-
通过 C++ 扩展将这些类型注册为 NumPy 可识别的
dtype,并支持相应的ufunc与类型转换规则。 -
在 Python 层对外导出这些数据类型,使用户可以像使用普通 NumPy dtype 一样直接使用它们。
不同浮点精度的可视比较


注:
- TF32 实际有效位数只有 19 位。TF32 是 NVIDIA Tensor Core 的内部计算格式,用户代码中的张量仍然是 FP32。
- FP32 $\to$ BF16:FP32 直接丢弃后 16 位得到 BF16。
评论