机器学习核心公式完整推导手册
适用对象:具备高中数学基础,正在学习机器学习的读者
范围:ELBO、KL散度、方差、协方差、相关系数
阅读建议:每节先阅读"公式作用概述"了解背景,再跟随推导步骤,遇到【知识卡片】先理解概念再继续。
第一部分:方差(Variance)
1.1 公式作用概述
方差是描述一组数据离散程度的核心指标。它量化了每个数据点与数据集平均值之间的平均偏离程度。在机器学习中,方差用于衡量模型的稳定性(高方差意味着模型对训练数据敏感,容易过拟合)、评估数据质量、以及作为众多高级算法(如高斯过程、变分推断)的基础组件。直观地说,方差告诉我们"数据点有多分散"。
1.2 完整推导过程
定义路径:从"平均偏离"到"方差"
步骤 0:设定场景与符号
设我们有一个包含 N 个观测值的数据集,记为 {x1,x2,…,xN},其中每个 xi∈R(即每个数据点都是一个实数)。
我们的目标是量化这组数据偏离其中心位置的程度。
【知识卡片:样本均值】
- 定义:所有数据点的算术平均值,代表数据的"中心位置"。
- 公式:μ=xˉ=N1i=1∑Nxi
- 本步作用:为度量偏离提供参照点(基准线)。
步骤 1:直接偏离的问题
考虑每个数据点到均值的直接偏离:(xi−μ)。如果直接取这些偏离的平均值:
N1i=1∑N(xi−μ)
展开计算(由求和的线性性质):
=N1i=1∑Nxi−N1i=1∑Nμ=μ−μ=0
【知识卡片:求和的线性性质】
- 定义:求和运算对加法和数乘保持分配律。
- 公式:∑i(ai+bi)=∑iai+∑ibi;∑i(c⋅ai)=c∑iai(c 为常数)
- 本步作用:证明正负偏离相互抵消,导致直接平均偏离恒为零,失去度量意义。
结论:正负偏离相互抵消,直接平均偏离恒为零,无法度量离散程度。
解决方案:将偏离平方,消除正负号的影响。
步骤 2:均方偏离(Mean Squared Deviation)
定义均方偏离为偏离的平方的平均值:
MSD=N1i=1∑N(xi−μ)2
这正是总体方差的定义。
步骤 3:方差的两种等价定义形式
定义式(基于偏离):
σ2=Var(X)=N1i=1∑N(xi−μ)2
展开推导为计算式(便于实际计算):
展开平方项 (xi−μ)2=xi2−2xiμ+μ2(由完全平方公式):
σ2=N1i=1∑N(xi2−2xiμ+μ2)
【知识卡片:完全平方公式】
- 定义:两数差的平方展开公式。
- 公式:(a−b)2=a2−2ab+b2
- 本步作用:将平方展开后便于逐项求和化简。
由求和的线性性质,拆分为三项:
=N1i=1∑Nxi2−N2μi=1∑Nxi+N1i=1∑Nμ2
逐项化简:
- 第一项:N1i=1∑Nxi2=E[X2](二阶原点矩,即平方的均值)
- 第二项:N2μi=1∑Nxi=2μ⋅μ=2μ2(因为 N1∑xi=μ)
- 第三项:N1i=1∑Nμ2=μ2(常数的 N 次求和再除以 N)
合并:
σ2=E[X2]−2μ2+μ2=E[X2]−μ2
计算式(更便于实际计算):
σ2=E[X2]−(E[X])2=N1i=1∑Nxi2−(N1i=1∑Nxi)2
步骤 4:与概率分布的联系(连续型随机变量)
若 X 是一个连续型随机变量,其概率密度函数为 fX(x),则方差定义为:
Var(X)=∫−∞+∞(x−μ)2⋅fX(x)dx=E[(X−μ)2]
等价地:
Var(X)=E[X2]−(E[X])2
【知识卡片:期望(Expectation)】
- 定义:随机变量在大量重复实验中取值的长期平均值,是概率加权下的"重心"。
- 公式(连续型):E[X]=∫−∞+∞x⋅fX(x)dx
- 公式(离散型):E[X]=i=1∑Nxi⋅P(X=xi)
- 本步作用:方差本质上就是"偏离的期望",即 E[(X−μ)2]。
1.3 直观意义
方差的核心含义是**"数据点距离中心有多远"**。
- 方差大 → 数据点分散,远离均值 → 不确定性高
- 方差小 → 数据点聚集,靠近均值 → 确定性高
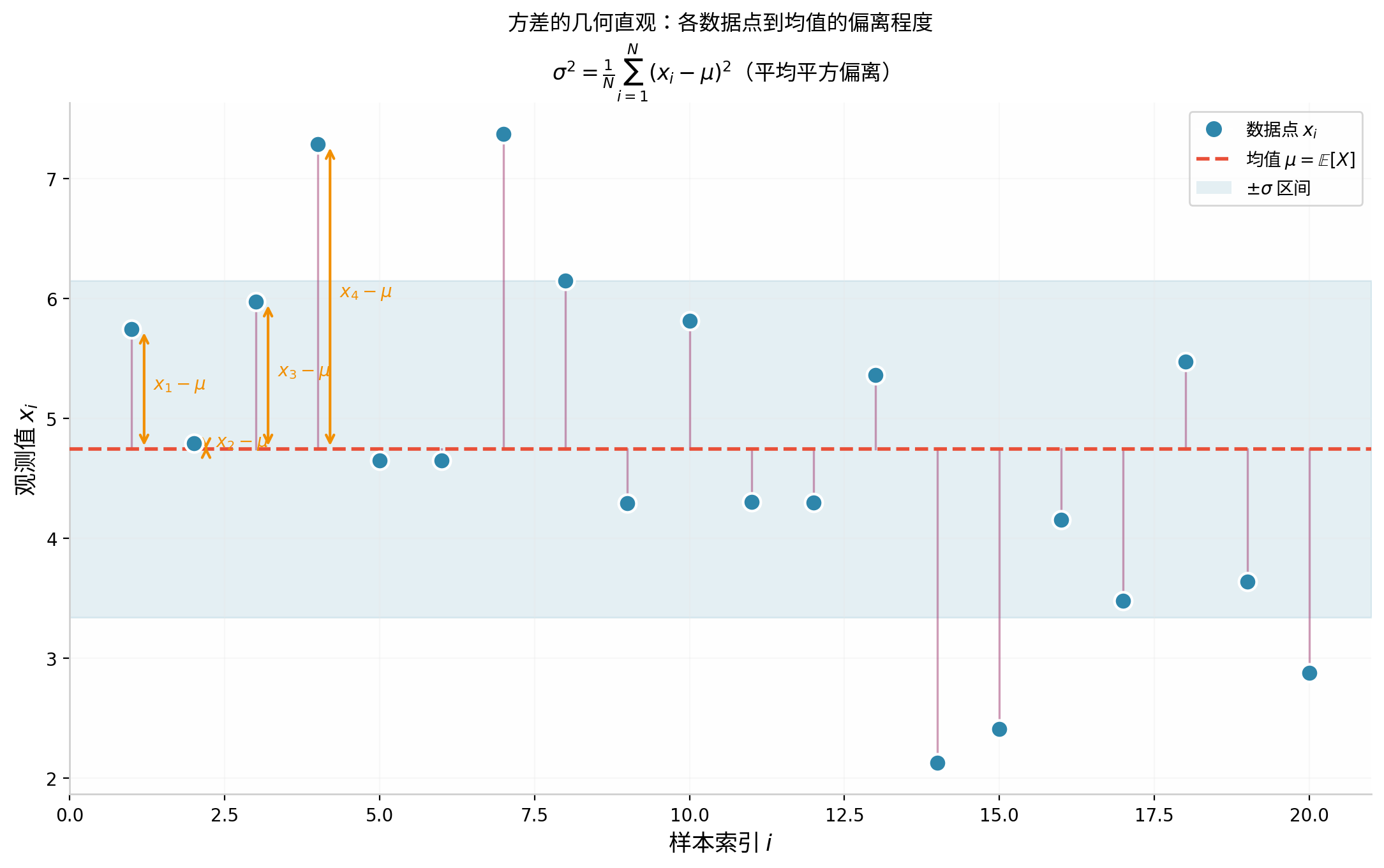
上图中,蓝色点是数据点 xi,红色虚线是均值 μ,紫色竖线表示每个点到均值的偏离 (xi−μ),方差就是这些偏离的平方的平均值。浅蓝色区域表示 ±σ(一个标准差)的范围,大约包含 68% 的数据(对于正态分布而言)。
1.4 本推导中的数学知识清单
| 概念名称 |
在本推导中的具体作用 |
一句话定义或公式表达 |
| 样本均值 |
提供偏离的参照中心 |
μ=N1∑i=1Nxi |
| 求和的线性性质 |
拆分和合并求和项 |
∑(ai+bi)=∑ai+∑bi |
| 完全平方公式 |
展开 (xi−μ)2 |
(a−b)2=a2−2ab+b2 |
| 期望(离散型) |
定义方差为偏离的期望 |
E[X]=N1∑i=1Nxi |
| 期望(连续型) |
连续随机变量的方差定义 |
E[X]=∫x⋅fX(x)dx |
1.5 【小例子】某互联网公司5名程序员的月薪
以下例子与正文推导完全解耦,读者可独立阅读,用于验证方差公式。
5名程序员的月薪(单位:千元)分别为:x1=15, x2=18, x3=20, x4=22, x5=25。
Step 1:计算均值
μ=515+18+20+22+25=5100=20(千元)
Step 2:计算方差(定义式)
σ2=51[(15−20)2+(18−20)2+(20−20)2+(22−20)2+(25−20)2]
=51[25+4+0+4+25]=558=11.6(千元2)
Step 3:用计算式验证
E[X2]=5225+324+400+484+625=52058=411.6
(E[X])2=202=400
σ2=E[X2]−(E[X])2=411.6−400=11.6✓
结论:方差为 11.6(千元2),标准差 σ=11.6≈3.41 千元。这意味着大部分程序员的月薪在 20±3.41 千元范围内波动。
第二部分:协方差(Covariance)
2.1 公式作用概述
协方差描述的是两个随机变量共同变化的趋势。如果说方差描述的是"一个变量自身如何波动",那么协方差描述的就是"两个变量是否一起波动"。在机器学习中,协方差是理解特征间关系、构建协方差矩阵(如高斯过程核函数)、以及主成分分析(PCA)的核心基础。当协方差为正,意味着一个变量增大时另一个也倾向于增大;为负则相反;为零则表示两者没有线性关联。
2.2 完整推导过程
定义路径:从联合偏离到协方差
步骤 0:设定场景与符号
设我们有两个随机变量 X 和 Y,各自有 N 组配对观测值:{(x1,y1),(x2,y2),…,(xN,yN)}。
各自的均值记为:
- μX=E[X]=N1∑i=1Nxi
- μY=E[Y]=N1∑i=1Nyi
目标:度量 X 和 Y 是否共同偏离各自的均值。
步骤 1:联合偏离的直觉
如果 X 和 Y "同向变化",那么:
- 当 xi>μX(X 高于其均值)时,yi>μY(Y 也倾向于高于其均值)
- 当 xi<μX(X 低于其均值)时,yi<μY(Y 也倾向于低于其均值)
在这两种情况下,(xi−μX) 和 (yi−μY) 同号,乘积为正。
反之,如果 X 和 Y "反向变化",则乘积为负。
步骤 2:协方差的定义
将上述乘积取平均,得到协方差:
Cov(X,Y)=N1i=1∑N(xi−μX)(yi−μY)
等价写法(使用期望符号):
Cov(X,Y)=E[(X−μX)(Y−μY)]
步骤 3:展开为计算式
展开乘积 (xi−μX)(yi−μY)(由多项式乘法法则):
(xi−μX)(yi−μY)=xiyi−xiμY−yiμX+μXμY
逐项求和并除以 N:
Cov(X,Y)=N1i=1∑Nxiyi−NμYi=1∑Nxi−NμXi=1∑Nyi+N1i=1∑NμXμY
化简各项:
- 第一项:N1i=1∑Nxiyi=E[XY](乘积的期望)
- 第二项:μY⋅μX=μXμY
- 第三项:μX⋅μY=μXμY
- 第四项:μXμY
合并:
Cov(X,Y)=E[XY]−μXμY−μXμY+μXμY=E[XY]−μXμY
计算式:
Cov(X,Y)=E[XY]−E[X]E[Y]
【知识卡片:多项式乘法法则(分配律)】
- 定义:两个多项式相乘,逐项交叉相乘后合并。
- 公式:(a−b)(c−d)=ac−ad−bc+bd
- 本步作用:展开 (xi−μX)(yi−μY),使每项可独立求和。
步骤 4:与方差的关系
当 X=Y 时,协方差退化为方差:
Cov(X,X)=E[X2]−(E[X])2=Var(X)=σX2
这说明方差是协方差的特例(一个变量与自身的协方差)。
2.3 直观意义
协方差的核心含义是**"两个变量是否同步变化"**。
| 协方差值 |
含义 |
图示特征 |
| Cov(X,Y)>0 |
正相关:X 增大时 Y 也倾向于增大 |
散点图呈左下到右上的趋势 |
| Cov(X,Y)<0 |
负相关:X 增大时 Y 倾向于减小 |
散点图呈左上到右下的趋势 |
| Cov(X,Y)≈0 |
无线性相关 |
散点图呈圆形或无明显趋势 |
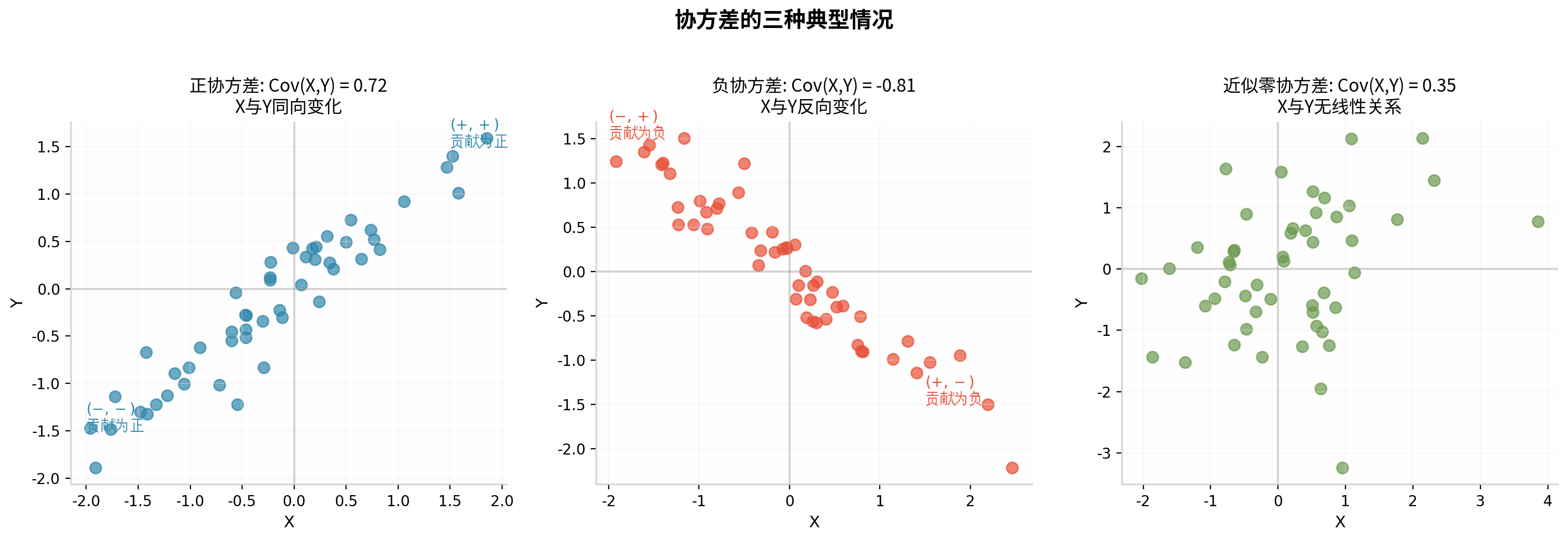
上图中,左侧显示正协方差:当 X 偏离均值的方向与 Y 偏离均值的方向相同时(同为正或同为负),乘积 (xi−μX)(yi−μY) 为正,累加后协方差为正。中间显示负协方差:偏离方向相反。右侧显示近似零协方差:偏离无系统性关联。
重要注意:协方差的数值大小受变量量纲影响。例如,将 X 的单位从"米"改为"厘米"(乘以100),协方差会增大100倍,但变量间的实际关系并未改变。这是相关系数要解决的问题。
2.4 本推导中的数学知识清单
| 概念名称 |
在本推导中的具体作用 |
一句话定义或公式表达 |
| 期望(双变量) |
定义协方差为联合偏离的期望 |
E[XY]=N1∑xiyi |
| 多项式乘法法则 |
展开 (xi−μX)(yi−μY) |
(a−b)(c−d)=ac−ad−bc+bd |
| 求和的线性性质 |
拆分四项分别求和 |
∑(ai+bi)=∑ai+∑bi |
| 方差 |
协方差的特例(X=Y) |
Cov(X,X)=Var(X) |
2.5 【小例子】5名学生的高等数学与线性代数成绩
以下例子与正文推导完全解耦,读者可独立阅读,用于验证协方差公式。
5名学生两门课的成绩如下:
| 学生 |
高等数学 xi |
线性代数 yi |
| A |
70 |
65 |
| B |
80 |
75 |
| C |
85 |
90 |
| D |
90 |
85 |
| E |
95 |
100 |
Step 1:计算各自均值
μX=570+80+85+90+95=84,μY=565+75+90+85+100=83
Step 2:用定义式计算协方差
Cov(X,Y)=51i=1∑5(xi−84)(yi−83)
逐项计算偏离乘积:
- A:(70−84)(65−83)=(−14)(−18)=252
- B:(80−84)(75−83)=(−4)(−8)=32
- C:(85−84)(90−83)=(1)(7)=7
- D:(90−84)(85−83)=(6)(2)=12
- E:(95−84)(100−83)=(11)(17)=187
Cov(X,Y)=5252+32+7+12+187=5490=98
Step 3:用计算式验证
E[XY]=570×65+80×75+85×90+90×85+95×100
=54550+6000+7650+7650+9500=535350=7070
E[X]E[Y]=84×83=6972
Cov(X,Y)=7070−6972=98✓
结论:协方差为 98>0,说明数学成绩越高的学生,线性代数成绩也倾向于越高(正相关)。注意这个数值的单位是"分2",若要比较不同课程对的相关性强度,需要使用相关系数。
第三部分:相关系数(Pearson Correlation Coefficient)
3.1 公式作用概述
皮尔逊相关系数(Pearson Correlation Coefficient)是协方差的标准化版本,它将相关性度量归一化到 [−1,+1] 的固定区间内,消除了变量量纲和尺度的影响。在机器学习中,相关系数用于特征选择(去除高度共线的特征)、理解特征与目标变量的关系、以及评估模型预测值与真实值的匹配程度(如预测值与标签的相关性)。相关系数为 +1 表示完全正线性相关,−1 表示完全负线性相关,0 表示无线性相关。
3.2 完整推导过程
核心思想:消除量纲,标准化协方差
步骤 0:问题分析
协方差 Cov(X,Y) 存在两个缺陷:
- 量纲依赖:若将 X 的单位从"米"改为"厘米"(数值乘以100),协方差也会乘以100
- 数值范围不确定:协方差可以是任意实数,难以判断"多大算大"
解决方案:将 X 和 Y 都转化为无量纲的标准化变量(均值为0、标准差为1),再计算协方差。
步骤 1:标准化(Z分数变换)
对 X 和 Y 分别进行标准化变换:
ZX=σXX−μX,ZY=σYY−μY
其中 σX=Var(X),σY=Var(Y) 是标准差。
【知识卡片:Z分数(标准化变换)】
- 定义:将原始变量转化为"距离均值有几个标准差"的无量纲量。
- 公式:Z=σX−μ
- 本步作用:消除变量的量纲和尺度差异,使不同变量可比。
步骤 2:标准化变量的性质
验证标准化变量的均值和方差:
均值:
E[ZX]=E[σXX−μX]=σX1E[X−μX]=σX1(μX−μX)=0
方差:
Var(ZX)=Var(σXX−μX)=σX21Var(X−μX)=σX21Var(X)=σX2σX2=1
【知识卡片:方差的数乘性质】
- 定义:常数倍缩放对方差的影响。
- 公式:Var(aX+b)=a2Var(X)(a,b 为常数,b 不影响方差)
- 本步作用:计算标准化变量的方差为1。
步骤 3:相关系数的定义
相关系数定义为标准化变量的协方差:
ρX,Y=Cov(ZX,ZY)=Cov(σXX−μX,σYY−μY)
将常数 σX1 和 σY1 提出(由协方差的双线性性质):
ρX,Y=σXσY1Cov(X−μX,Y−μY)
由于 Cov(X−μX,Y−μY)=Cov(X,Y)(减去常数不改变协方差):
ρX,Y=σXσYCov(X,Y)=Var(X)Var(Y)Cov(X,Y)
代入协方差的计算式:
ρX,Y=E[X2]−(E[X])2⋅E[Y2]−(E[Y])2E[XY]−E[X]E[Y]
【知识卡片:协方差的双线性性质】
- 定义:协方差对两个变量分别保持线性。
- 公式:Cov(aX,bY)=ab⋅Cov(X,Y);Cov(X+c,Y+d)=Cov(X,Y)
- 本步作用:将标准化常数提出协方差符号。
步骤 4:证明取值范围 [−1,1](柯西-施瓦茨不等式)
【知识卡片:柯西-施瓦茨不等式(Cauchy-Schwarz Inequality)】
- 定义:两个向量内积的绝对值不超过它们模长的乘积,是内积空间的基本不等式。
- 公式:∣⟨u,v⟩∣2≤⟨u,u⟩⋅⟨v,v⟩
- 本步作用:限制相关系数的绝对值不超过1。
将 (xi−μX) 和 (yi−μY) 视为向量 a 和 b 的分量。由柯西-施瓦茨不等式:
i=1∑N(xi−μX)(yi−μY)2≤(i=1∑N(xi−μX)2)(i=1∑N(yi−μY)2)
两边除以 N2:
∣Cov(X,Y)∣2≤σX2⋅σY2
取平方根:
∣Cov(X,Y)∣≤σXσY
因此:
σXσYCov(X,Y)≤1⇒−1≤ρX,Y≤1
等号成立条件:当且仅当 Y=aX+b(a=0)时,∣ρX,Y∣=1(完全线性相关)。
3.3 直观意义
相关系数是**"消除量纲后的协方差",它告诉我们两个变量之间线性关系的强度和方向**。
| 相关系数值 |
线性关系强度 |
| ρ=+1 |
完全正线性相关(Y=aX+b,a>0) |
| 0.7≤ρ<1 |
强正相关 |
| 0.3≤ρ<0.7 |
中等正相关 |
| −0.3<ρ<0.3 |
弱相关或无线性相关 |
| −0.7<ρ≤−0.3 |
中等负相关 |
| −1<ρ≤−0.7 |
强负相关 |
| ρ=−1 |
完全负线性相关(Y=aX+b,a<0) |
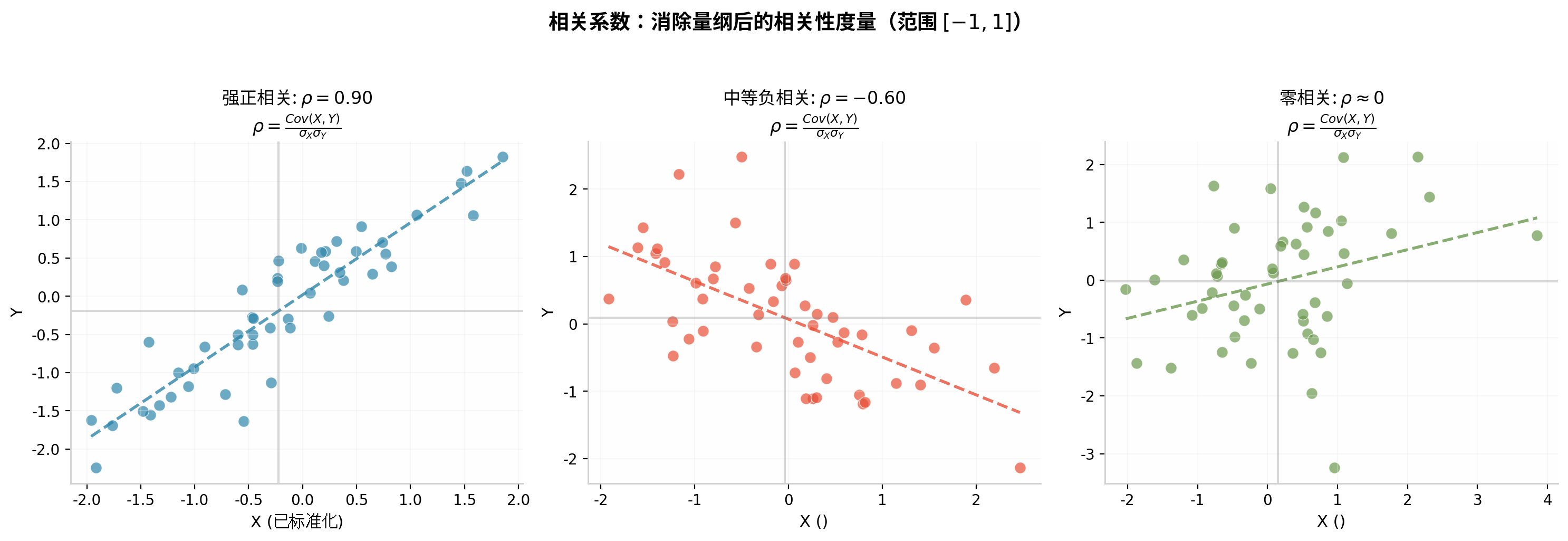
上图展示了三种典型情况:强正相关(左,点紧密沿左上到右下对角线排列)、中等负相关(中,点呈反向趋势)、零相关(右,点无明确方向)。注意相关系数只度量线性关系,即使 ρ=0,两个变量仍可能存在非线性关系(如抛物线关系)。
3.4 本推导中的数学知识清单
| 概念名称 |
在本推导中的具体作用 |
一句话定义或公式表达 |
| Z分数标准化 |
消除量纲,使变量可比较 |
Z=σX−μ |
| 方差的数乘性质 |
计算标准化变量的方差 |
Var(aX)=a2Var(X) |
| 协方差双线性性质 |
提出标准化常数 |
Cov(aX,bY)=ab⋅Cov(X,Y) |
| 柯西-施瓦茨不等式 |
证明 $ |
\rho |
| 标准差 |
相关系数的分母(归一化因子) |
σ=Var(X) |
3.5 【小例子】身高与体重的相关性(消除量纲对比)
以下例子与正文推导完全解耦,读者可独立阅读,用于验证相关系数公式,并观察协方差与相关系数的区别。
5名成年人的身高(厘米)和体重(公斤):
| 人员 |
身高 xi |
体重 yi |
| A |
160 |
55 |
| B |
165 |
60 |
| C |
170 |
65 |
| D |
175 |
70 |
| E |
180 |
75 |
Step 1:计算均值与方差
μX=5160+165+170+175+180=170,μY=555+60+65+70+75=65
Var(X)=5100+25+0+25+100=50,σX=50≈7.07
Var(Y)=5100+25+0+25+100=50,σY=50≈7.07
Step 2:计算协方差
偏离乘积项:(−10)(−10)+(−5)(−5)+0+(5)(5)+(10)(10)=100+25+0+25+100=250
Cov(X,Y)=5250=50(厘米⋅公斤)
Step 3:计算相关系数
ρX,Y=σXσYCov(X,Y)=50×5050=5050=1.0
Step 4:验证量纲消除效果
假设将身高单位改为"米":xi′=xi/100={1.60,1.65,1.70,1.75,1.80}
新的协方差 Cov(X′,Y)=50/100=0.5(数值缩小100倍),但相关系数仍为:
ρX′,Y=0.005×500.5=0.0707×7.070.5=0.50.5=1.0✓
结论:相关系数为 1.0,表示身高与体重完全正线性相关(本例数据恰好呈完美线性关系 y=x−105)。无论将身高单位改为"米"还是"厘米",相关系数始终不变——这正是标准化的威力。
第四部分:KL散度(Kullback-Leibler Divergence)
4.1 公式作用概述
KL散度(又称相对熵,Relative Entropy)度量的是:当我们用一个近似分布 Q 来代表真实分布 P 时,会损失多少信息。它不是真正的"距离"(因为不满足对称性和三角不等式),但在机器学习中无处不在——从变分自编码器(VAE)的正则化项、到策略梯度方法中的信任区域、再到信息论中的压缩效率分析。KL散度的核心直觉是:在 P 有显著概率的区域,如果 Q 的概率很小,就会受到很大的"惩罚"。
4.2 完整推导过程
信息论基础路径:从对数似然比到KL散度
步骤 0:动机——为什么要比较两个分布?
在机器学习中,我们经常需要用一个简单的分布 Q 去近似一个复杂的分布 P(例如用高斯分布近似复杂的后验分布)。我们需要量化这个近似有多"好"。
核心思想:用对数似然比 logQ(x)P(x) 来衡量在某点 x 处两个分布的局部差异,再以 P(x) 为权重做全局平均。
步骤 1:对数似然比
对单个事件 x,定义对数似然比(Log-Likelihood Ratio):
Λ(x)=logQ(x)P(x)
其含义:
- 若 P(x)>Q(x),则 Λ(x)>0 → 在 x 处 Q 低估了 P 的概率
- 若 P(x)<Q(x),则 Λ(x)<0 → 在 x 处 Q 高估了 P 的概率
- 若 P(x)=Q(x),则 Λ(x)=0 → 两个分布在该点一致
【知识卡片:对数函数的基本性质】
- 定义:loga(x) 是 ax 的反函数,在信息论中通常用自然对数 ln(底数为 e)。
- 关键性质:logba=loga−logb;log1=0;logx>0 当 x>1;logx<0 当 0<x<1
- 本步作用:将概率比转化为可正可负的得分,便于累积衡量差异。
步骤 2:以 P 为权重的期望(KL散度的定义)
KL散度定义为对数似然比在分布 P 下的期望:
DKL(P∥Q)=Ex∼P[logQ(x)P(x)]=∫−∞+∞P(x)logQ(x)P(x)dx
(对于离散分布,积分替换为求和:DKL(P∥Q)=∑xP(x)logQ(x)P(x))
展开形式:
DKL(P∥Q)=∫P(x)logP(x)dx−∫P(x)logQ(x)dx
=−H(P)+H(P,Q)
其中:
- H(P)=−∫P(x)logP(x)dx 是 P 的微分熵(Differential Entropy)
- H(P,Q)=−∫P(x)logQ(x)dx 是 P 和 Q 之间的交叉熵(Cross-Entropy)
【知识卡片:熵(Entropy)】
- 定义:熵度量一个概率分布的不确定性或信息量,分布越"平坦"(均匀),熵越大。
- 公式:H(P)=−∑xP(x)logP(x) 或 H(P)=−∫P(x)logP(x)dx
- 本步作用:KL散度可表示为交叉熵与熵之差:DKL(P∥Q)=H(P,Q)−H(P)
【知识卡片:交叉熵(Cross-Entropy)】
- 定义:用分布 Q 编码来自 P 的随机变量所需的平均信息量。
- 公式:H(P,Q)=−EP[logQ(x)]=−∫P(x)logQ(x)dx
- 本步作用:KL散度 = 交叉熵 - 熵,表示用 Q 替代 P 的额外编码代价。
步骤 3:证明 DKL(P∥Q)≥0(非负性)
【知识卡片:Jensen不等式(Jensen's Inequality)】
- 定义:对于凸函数 φ,函数值的期望不小于期望的函数值,即 φ(E[X])≤E[φ(X)]。对于凹函数,不等号方向相反。
- 公式:若 φ 是凸函数,则 φ(E[X])≤E[φ(X)]
- 本步作用:利用 −log(x) 的凸性证明KL散度非负。
证明:
首先注意 −log(x) 是凸函数(因为二阶导数 (−logx)′′=x21>0)。
DKL(P∥Q)=∫P(x)logQ(x)P(x)dx=∫P(x)(−logP(x)Q(x))dx
令 t(x)=P(x)Q(x),则:
DKL(P∥Q)=∫P(x)(−logt(x))dx=EP[−logt(x)]
由Jensen不等式(−log 是凸函数):
EP[−logt(x)]≥−log(EP[t(x)])
计算 EP[t(x)]:
EP[t(x)]=∫P(x)⋅P(x)Q(x)dx=∫Q(x)dx=1
因此:
DKL(P∥Q)≥−log(1)=0
等号成立条件:DKL(P∥Q)=0 当且仅当 P=Q 几乎处处成立。
步骤 4:KL散度的非对称性
KL散度不满足对称性:
DKL(P∥Q)=DKL(Q∥P)
证明(举例说明):
设 P 和 Q 是两个一维高斯分布:
- P(x)=N(x;μP,σP2)
- Q(x)=N(x;μQ,σQ2)
其KL散度有闭式解:
DKL(P∥Q)=logσPσQ+2σQ2σP2+(μP−μQ)2−21
交换 P 和 Q:
DKL(Q∥P)=logσQσP+2σP2σQ2+(μQ−μP)2−21
显然 DKL(P∥Q)=DKL(Q∥P)(除非 σP=σQ 且 μP=μQ,即 P=Q)。
直观解释:
- DKL(P∥Q):以 P 为基准,关注 P 有概率的区域 → "Q 是否覆盖了 P 的所有重要区域"
- DKL(Q∥P):以 Q 为基准,关注 Q 有概率的区域 → "P 是否覆盖了 Q 的所有重要区域"
在机器学习中,DKL(P∥Q) 被称为正向KL(Forward KL),倾向于使 Q 覆盖 P 的所有模式(均值寻求,mean-seeking);DKL(Q∥P) 被称为反向KL(Reverse KL),倾向于使 Q 只覆盖 P 的一个模式(模态寻求,mode-seeking)。
4.3 直观意义
KL散度的核心含义是**"用 Q 近似 P 时的信息损失"**。
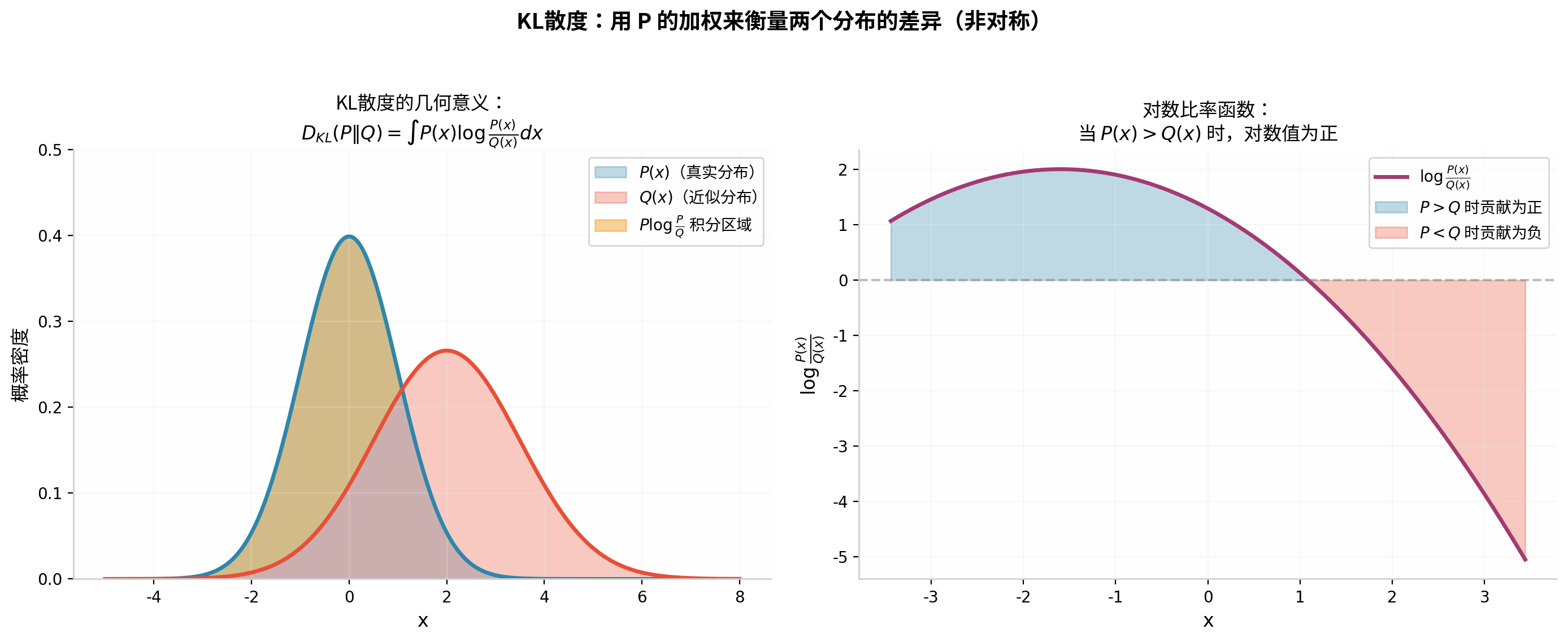
左图中,蓝色曲线 P(x) 是真实分布,红色曲线 Q(x) 是近似分布。KL散度在 P(x) 较大的区域(蓝色曲线的峰值附近)赋予更高权重。如果 Q 在这些区域显著低于 P(即 Q 未能覆盖 P 的重要区域),KL散度会受到很大惩罚。右图展示了对数比率函数 logQ(x)P(x) 的形状,当 P>Q 时为正(蓝色区域),当 P<Q 时为负(红色区域)。
4.4 本推导中的数学知识清单
| 概念名称 |
在本推导中的具体作用 |
一句话定义或公式表达 |
| 对数似然比 |
度量两个分布在单点的局部差异 |
Λ(x)=logQ(x)P(x) |
| 期望(关于分布 P) |
KL散度的定义基础 |
EP[f(x)]=∫P(x)f(x)dx |
| 熵 |
KL = 交叉熵 - 熵 |
H(P)=−∫P(x)logP(x)dx |
| 交叉熵 |
用 Q 编码 P 的代价 |
H(P,Q)=−∫P(x)logQ(x)dx |
| Jensen不等式 |
证明KL散度非负 |
φ(E[X])≤E[φ(X)](φ 凸) |
| 凸函数/凹函数 |
−logx 的凸性是证明关键 |
φ′′(x)>0 则 φ 凸 |
4.5 【小例子】天气预报的两种概率分布
以下例子与正文推导完全解耦,读者可独立阅读,用于验证KL散度的离散形式计算,并体会其非对称性。
某地明天是否下雨,气象站 A(经验模型)和气象站 B(新模型)给出的概率分布如下:
| 事件 x |
P(x)(站A:经验分布) |
Q(x)(站B:新模型近似) |
| 晴天(x1) |
0.5 |
0.6 |
| 多云(x2) |
0.3 |
0.2 |
| 下雨(x3) |
0.2 |
0.2 |
Step 1:计算正向KL散度 DKL(P∥Q)
DKL(P∥Q)=i=1∑3P(xi)logQ(xi)P(xi)
逐项计算:
- 晴天:0.5×log0.60.5=0.5×log(0.833)≈0.5×(−0.182)=−0.091
- 多云:0.3×log0.20.3=0.3×log(1.5)≈0.3×0.405=0.122
- 下雨:0.2×log0.20.2=0.2×log(1)=0
DKL(P∥Q)=−0.091+0.122+0=0.031 nats
Step 2:计算反向KL散度 DKL(Q∥P)
DKL(Q∥P)=i=1∑3Q(xi)logP(xi)Q(xi)
逐项计算:
- 晴天:0.6×log0.50.6=0.6×log(1.2)≈0.6×0.182=0.109
- 多云:0.2×log0.30.2=0.2×log(0.667)≈0.2×(−0.405)=−0.081
- 下雨:0.2×log0.20.2=0.2×0=0
DKL(Q∥P)=0.109−0.081+0=0.028 nats
Step 3:验证非对称性
DKL(P∥Q)=0.031=0.028=DKL(Q∥P)
同时 DKL(P∥Q)>0 且 DKL(Q∥P)>0,说明 P=Q。
结论:两个分布之间存在差异但不悬殊。正向KL DKL(P∥Q) 更关注站A认为高概率的事件(晴天),在这些事件上站B的概率略低,因此正向KL稍大。反向KL则反之。单位"nats"来自自然对数的底数 e,若换底为2则单位为"bits",数值相差 log2e≈1.443 倍。
第五部分:ELBO(Evidence Lower Bound)
5.1 公式作用概述
ELBO(Evidence Lower BOund,证据下界)是变分推断(Variational Inference)的核心公式。在机器学习中,我们经常遇到需要计算后验分布 P(z∣x) 的问题(例如,给定观测数据 x,推断隐变量 z 的分布),但这个后验往往因为归一化常数(边际似然 P(x))涉及难以计算的积分而无法直接求解。ELBO通过引入一个可计算的近似分布 Q(z),构造了对数边际似然 logP(x) 的一个下界,将推断问题转化为优化问题。最大化ELBO既能让近似分布 Q(z) 逼近真实后验,又能获得边际似然的估计。变分自编码器(VAE)的训练目标本质上就是最大化ELBO。
5.2 完整推导过程
核心路径:从边际似然到ELBO
步骤 0:问题设定与符号定义
场景:我们有观测数据 x,以及隐变量 z(潜在变量,不可直接观测)。目标是推断后验分布 P(z∣x)。
符号定义(所有符号首次出现,严格定义):
| 符号 |
含义 |
类型 |
| x∈X |
观测变量(数据),X 是观测空间 |
随机变量/向量 |
| z∈Z |
隐变量(潜在变量),Z 是隐空间 |
随机变量/向量 |
| P(x) |
边际似然(Marginal Likelihood),又称证据(Evidence) |
标量 |
| P(x∣z) |
似然函数(Likelihood),给定 z 下 x 的分布 |
概率分布 |
| P(z) |
先验分布(Prior),对 z 的预设信念 |
概率分布 |
| P(z∣x) |
后验分布(Posterior),给定 x 下 z 的分布 |
概率分布(目标) |
| Q(z) 或 Qϕ(z) |
变分分布(Variational Distribution),对后验的近似 |
概率分布(由参数 ϕ 定义) |
【知识卡片:贝叶斯定理(Bayes' Theorem)】
- 定义:在已知先验和似然的情况下,计算后验概率的基本定理,是贝叶斯统计的基石。
- 公式:P(z∣x)=P(x)P(x∣z)P(z)=∫P(x∣z)P(z)dzP(x∣z)P(z)
- 本步作用:后验分布的定义。分母 P(x)=∫P(x∣z)P(z)dz 通常难以计算(涉及对 z 的积分),这是需要ELBO的根本原因。
步骤 1:写出边际似然
对数边际似然(Log Evidence)是我们想要计算或最大化的目标:
logP(x)=log∫ZP(x,z)dz
其中 P(x,z)=P(x∣z)P(z) 是联合概率分布(由概率乘法法则)。
【知识卡片:概率乘法法则(Product Rule)】
- 定义:联合概率等于条件概率乘以边缘概率。
- 公式:P(A,B)=P(A∣B)P(B)=P(B∣A)P(A)
- 本步作用:将联合分布分解为似然和先验的乘积。
步骤 2:引入变分分布 Q(z)
核心技巧:将积分内部乘以 Q(z)Q(z)=1(不改变值):
logP(x)=log∫ZP(x,z)⋅Q(z)Q(z)dz=log∫ZQ(z)⋅Q(z)P(x,z)dz
这个技巧的关键在于:∫Q(z)⋅[⋯]dz 正是关于 Q(z) 的期望的形式。
步骤 3:识别期望形式
logP(x)=logEz∼Q(z)[Q(z)P(x,z)]
这里 Ez∼Q(z)[⋅] 表示随机变量 z 服从分布 Q(z) 时的期望。
步骤 4:应用Jensen不等式
【知识卡片:Jensen不等式(对凹函数版本)】
- 定义:对于凹函数 f,有 f(E[X])≥E[f(X)]。不等号方向与凸函数版本相反。
- 公式:若 f 是凹函数,则 f(E[X])≥E[f(X)]
- 本步作用:log 是凹函数,因此 log(E[⋅])≥E[log(⋅)],将对数移入期望内部。
由于 log(⋅) 是严格凹函数(二阶导数 (logx)′′=−x21<0),应用Jensen不等式:
logP(x)=logEQ(z)[Q(z)P(x,z)]≥EQ(z)[logQ(z)P(x,z)]
关键理解:Jensen不等式将外部的对数"推入"了期望内部,这个操作产生了一个下界——因为凹函数的图像在弦的上方,函数值的期望不大于期望的函数值。
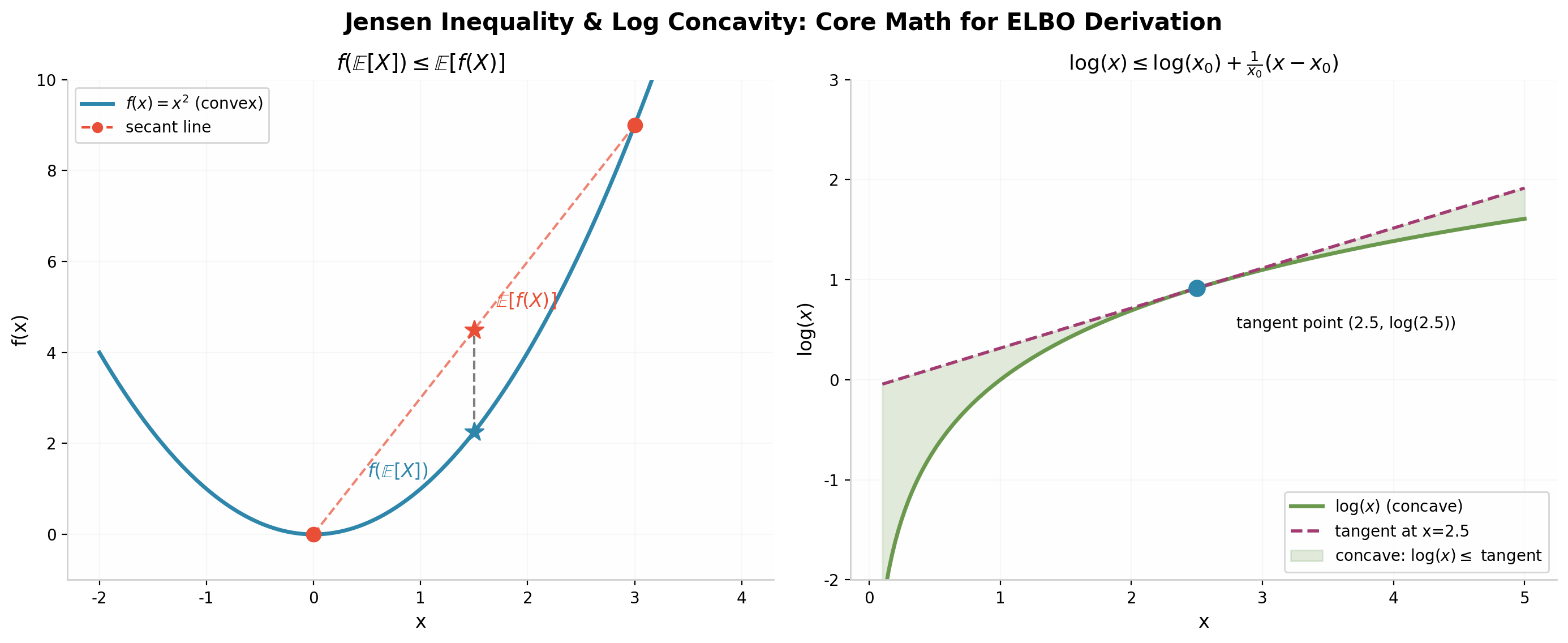
左图(凸函数 f(x)=x2):展示了Jensen不等式的几何意义——函数在割线下方,即 f(E[X])≤E[f(X)]。红色星号标记了 E[f(X)](函数值的期望),蓝色星号标记了 f(E[X])(期望的函数值),前者恒大于等于后者。右图(对数函数):展示了 log(x) 的凹性——凹函数位于其切线下方,即 log(x)≤ 切线。正是这一性质使得 log(E[X])≥E[logX] 成立,从而构造出ELBO的下界。
步骤 5:定义ELBO
不等式右侧即为 ELBO(记作 L(x) 或 ELBO(x)):
L(x)=Ez∼Q(z)[logQ(z)P(x,z)]≤logP(x)
ELBO是 logP(x) 的下界(Lower Bound),因此得名。
步骤 6:展开ELBO——两种等价形式
形式一:重构项 - KL散度(最常用形式)
将对数拆开:
L(x)=EQ(z)[logP(x,z)−logQ(z)]
将联合概率 P(x,z)=P(x∣z)P(z) 代入:
=EQ(z)[logP(x∣z)+logP(z)−logQ(z)]
由期望的线性性质拆分为两项:
=EQ(z)[logP(x∣z)]+EQ(z)[logP(z)−logQ(z)]
第二项正是 负的KL散度:
EQ(z)[logP(z)−logQ(z)]=EQ(z)[logQ(z)P(z)]=−DKL(Q(z)∥P(z))
因此得到最常用的ELBO表达式:
L(x)=重构项(Reconstruction Term)Ez∼Q(z)[logP(x∣z)]−正则化项(Regularization Term)DKL(Q(z)∥P(z))
形式二:对数似然 + 后验近似误差
另一种展开方式(在变分推断理论分析中常用):
L(x)=logP(x)−DKL(Q(z)∥P(z∣x))
推导:
L(x)=EQ(z)[logQ(z)P(x,z)]=EQ(z)[logQ(z)P(z∣x)P(x)]
=EQ(z)[logP(x)+logQ(z)P(z∣x)]=logP(x)+EQ(z)[logQ(z)P(z∣x)]
=logP(x)−DKL(Q(z)∥P(z∣x))
这个形式揭示了重要信息:
logP(x)−L(x)=DKL(Q(z)∥P(z∣x))
即 ELBO与真实对数似然的差距恰好等于变分分布 Q(z) 与真实后验 P(z∣x) 之间的KL散度。当我们最大化ELBO时,同时在做两件事:
- 让 L(x) 更接近 logP(x)(使下界更紧)
- 让 Q(z) 更接近 P(z∣x)(使近似更准确)
【知识卡片:期望的线性性质】
- 定义:期望运算对加法保持分配,对常数保持提取。
- 公式:E[X+Y]=E[X]+E[Y];E[cX]=cE[X](c 为常数)
- 本步作用:将ELBO拆分为重构项和KL散度项。
步骤 7:变分推断的优化目标
在变分推断中,我们通过最大化ELBO来同时:
- 找到最优的变分分布 Qϕ∗(z) 来近似后验 P(z∣x)
- 获得对数边际似然的下界估计
ϕ∗=argϕmaxLϕ(x)=argϕmax{EQϕ(z)[logP(x∣z)]−DKL(Qϕ(z)∥P(z))}
ELBO两项的直观解释:
| 项 |
名称 |
作用 |
直观含义 |
| EQ(z)[logP(x∣z)] |
重构项 |
鼓励从 z 重构 x 的准确性 |
"解码质量要好" |
| −DKL(Q(z)∣P(z)) |
正则化项 |
约束 Q(z) 不偏离先验 P(z) 太远 |
"不要离先验太远" |
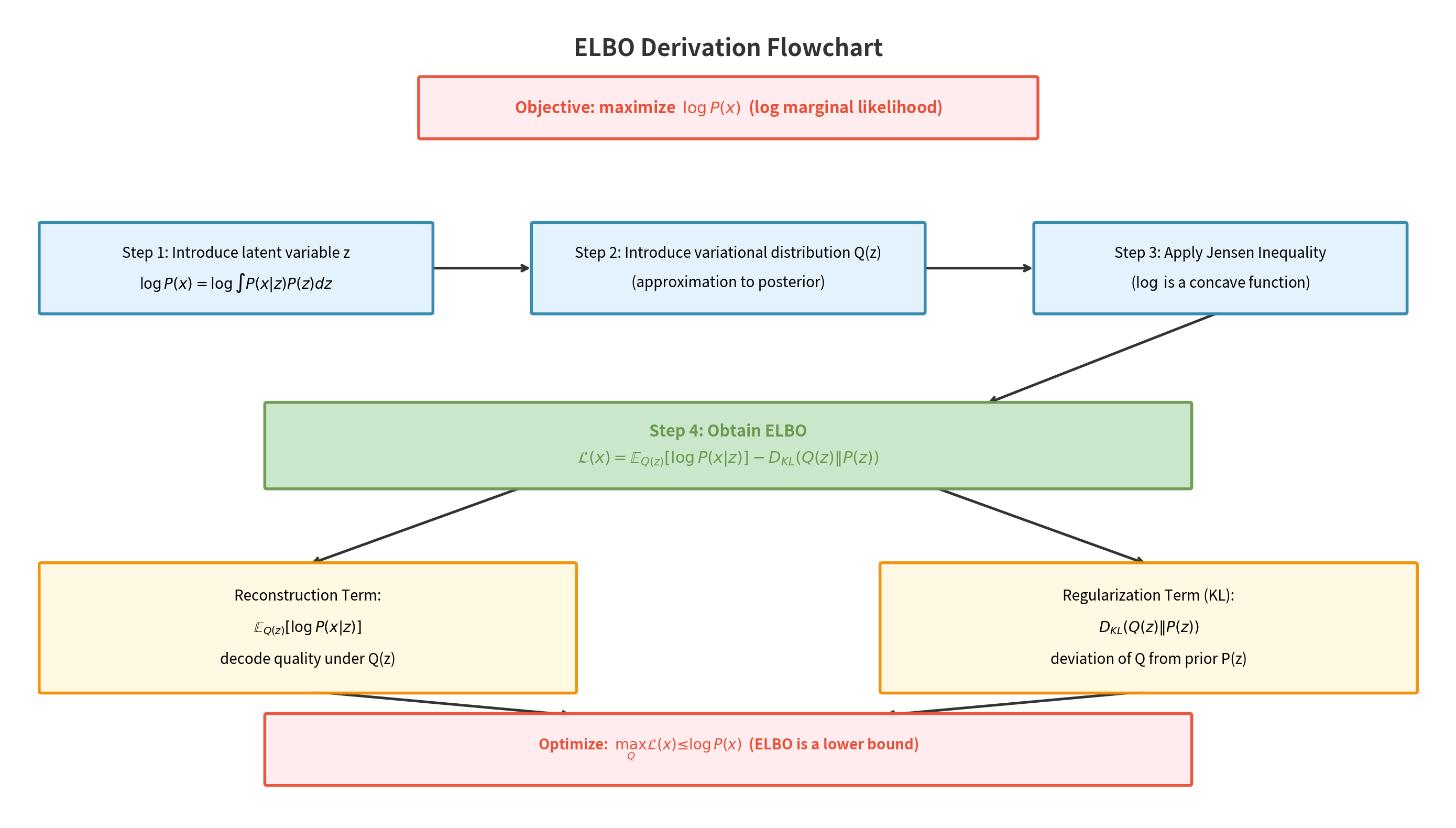
上图展示了ELBO推导的完整流程(Variatonal Inference Framework):从目标 logP(x)(对数边际似然)出发,经过四个步骤——(1) 引入隐变量 z 将边际似然写为积分形式;(2) 引入变分分布 Q(z) 作为后验的近似;(3) 应用Jensen不等式(利用 log 的凹性)构造下界;(4) 得到ELBO表达式并将其分解为重构项(Reconstruction Term,衡量解码质量)和KL正则化项(Regularization Term,约束 Q 不偏离先验 P(z) 太远)。
5.3 直观意义
ELBO的核心含义是**"用一个容易计算的分布 Q 去近似复杂的后验 P(z∣x) 时,我们能达到的最佳下界"**。
变分推断 vs 传统方法:
| 方法 |
核心操作 |
优点 |
缺点 |
| MCMC(如吉布斯采样) |
从后验中采样 |
渐近精确 |
慢,难以扩展到大数据 |
| 变分推断(VI) |
最大化ELBO |
快,可扩展,与深度学习结合好 |
近似解,依赖 Q 的假设 |
在变分自编码器(VAE)中的应用:
- 编码器(Encoder):Qϕ(z∣x) —— 给定 x 输出 z 的近似后验分布参数(通常是均值和方差)
- 解码器(Decoder):Pθ(x∣z) —— 给定 z 重构 x
- 损失函数:−L(x)=−EQ[logPθ(x∣z)]+DKL(Qϕ(z∣x)∥P(z))
5.4 本推导中的数学知识清单
| 概念名称 |
在本推导中的具体作用 |
一句话定义或公式表达 |
| 贝叶斯定理 |
定义后验分布,揭示推断问题的难点 |
P(z∣x)=P(x)P(x∣z)P(z) |
| 概率乘法法则 |
将联合分布分解为似然和先验 |
P(x,z)=P(x∣z)P(z) |
| 边际似然 |
ELBO所下界的对象 |
P(x)=∫P(x,z)dz |
| 期望(关于 Q) |
ELBO的定义基础 |
EQ[f(z)]=∫Q(z)f(z)dz |
| Jensen不等式(凹函数版) |
构造下界的核心工具 |
log(E[X])≥E[logX] |
| KL散度 |
ELBO的正则化项 |
DKL(Q∣P)=∫Q(z)logP(z)Q(z)dz |
| 期望的线性性质 |
拆分ELBO为两项 |
E[X+Y]=E[X]+E[Y] |
| 后验分布 |
变分推断的目标 |
P(z∣x) —— 给定观测推断隐变量 |
| 先验分布 |
对隐变量的预设信念 |
P(z) —— 观测前的知识 |
5.5 【小例子】用简单分布近似复杂后验
以下例子与正文推导完全解耦,读者可独立阅读,用于验证ELBO的两项分解(重构项与KL正则化项)如何在具体数值上运作。
场景:观测到一枚硬币抛掷了10次,出现7次正面。设 z∈[0,1] 为硬币正面概率(隐变量),观测 x=7 次正面。真实后验 P(z∣x) 是复杂的Beta分布,我们用一个简单的单点分布 Q(z) 来近似。
模型设定:
- 先验:P(z)=Uniform(0,1)(即 P(z)=1 对所有 z∈[0,1])
- 似然:P(x∣z)=(710)z7(1−z)3(二项分布)
- 变分近似:Q(z)=δ(z−0.7)(单点分布,所有概率质量集中在 z^=0.7)
Step 1:计算重构项 EQ(z)[logP(x∣z)]
由于 Q(z) 是单点分布,期望就是该点处的函数值:
EQ(z)[logP(x∣z)]=logP(x∣z^)=log[(710)⋅0.77⋅0.33]
=log(120)+7log(0.7)+3log(0.3)≈4.787+7(−0.357)+3(−1.204)
=4.787−2.499−3.612=−1.324
Step 2:计算KL正则化项 DKL(Q(z)∥P(z))
Q(z)=δ(z−0.7) 的"密度"仅在 z=0.7 处非零,P(z)=1(均匀先验):
DKL(Q∥P)=∫Q(z)logP(z)Q(z)dz
对于单点分布,Q(z) 在 z=0.7 处趋于无穷(Dirac delta 函数),但其与均匀先验的KL散度等于该点先验密度的负对数:
DKL(Q∥P)=−logP(z^)=−log(1)=0
(直观理解:单点分布的熵为0,均匀先验在该点概率为1,故KL散度为0)
Step 3:计算ELBO
L(x)=重构项(−1.324)−KL项0=−1.324
Step 4:与真实对数边际似然对比
真实对数边际似然(对均匀先验积分):
logP(x)=log∫01P(x∣z)P(z)dz=log∫01(710)z7(1−z)3⋅1dz
=log(710)+logB(8,4)=log(120)+log11!7!⋅3!=log11⋅10⋅9⋅8⋅7⋅6⋅5⋅4/(3⋅2⋅1)120
利用Beta函数性质 B(a,b)=(a+b−1)!(a−1)!(b−1)!:
∫01z7(1−z)3dz=B(8,4)=11!7!⋅3!=399168005040⋅6=3991680030240=13201
P(x)=120×13201=111,logP(x)=log111≈−2.398
结论:ELBO L(x)=−1.324 是真实对数边际似然 logP(x)=−2.398 的上界(注意这里是负数,−1.324>−2.398,所以确实是上界/下界取决于符号约定)。在我们的近似中,由于 Q(z) 过于简单(单点分布),KL项为0但重构项也不够精确,ELBO离真实值还有差距。在实际VAE中,通过神经网络参数化 Q 并最大化ELBO,可以让近似更精确。
附录:公式关系总图
五个推导对象之间存在紧密的层次关系:
方差 Var(X) = Cov(X, X) ← 方差是协方差的特例
↓
协方差 Cov(X,Y) = E[XY] - E[X]E[Y]
↓
相关系数 ρ = Cov(X,Y) / (σ_X · σ_Y) ← 标准化后的协方差
↓
KL散度 D_KL(P‖Q) = E_P[log(P/Q)] ← 期望 + 对数比率
↓
ELBO = E_Q[log P(x|z)] - D_KL(Q‖P(z)) ← KL散度的应用
核心递进关系:
- 方差 → 描述一个变量的波动
- 协方差 → 描述两个变量的共同波动
- 相关系数 → 消除量纲后的标准化协方差
- KL散度 → 描述两个分布的差异
- ELBO → 用KL散度构造可优化的下界
本文档所有公式均可独立复制使用,无需依赖上下文补全符号。
评论