Sequence Parallelism序列并行(一)
原始论文 Reducing Activation Recomputation in Large Transformer Models
序列并行
序列并行是在张量并行的基础上进行的进一步深度优化,旨在减少“中间值”带来的显存占用(“中间值”是反向传播所必需的。如果不保存这些中间值,在反向传播过程中就必须重新执行前向计算来生成它们,这会显著增加训练的时间开销)。^1
关于 Transformer 各层的显存占用分析,请参考我的文章:
关于张量并行,请参考我的文章:
“中间值”显存占用分析
符号约定
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| $a$ | number of attention heads | $p$ | pipeline parallel size |
| $b$ | microbatch size | $s$ | sequence length |
| $h$ | hidden dimension size | $t$ | tensor parallel size |
| $L$ | number of transformer layers | $v$ | vocabulary size |
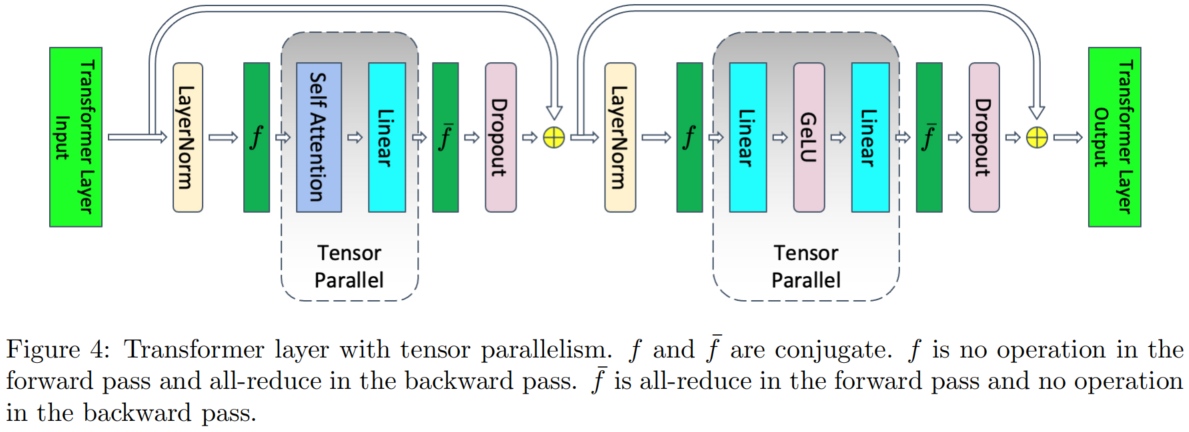
未采用并行机制的 Transformer 架构
架构如下图,我们主要关注图中灰色部分的 Transformer Layer,因为它会重复 $L$ 层,占显存开销的大头。
![]()
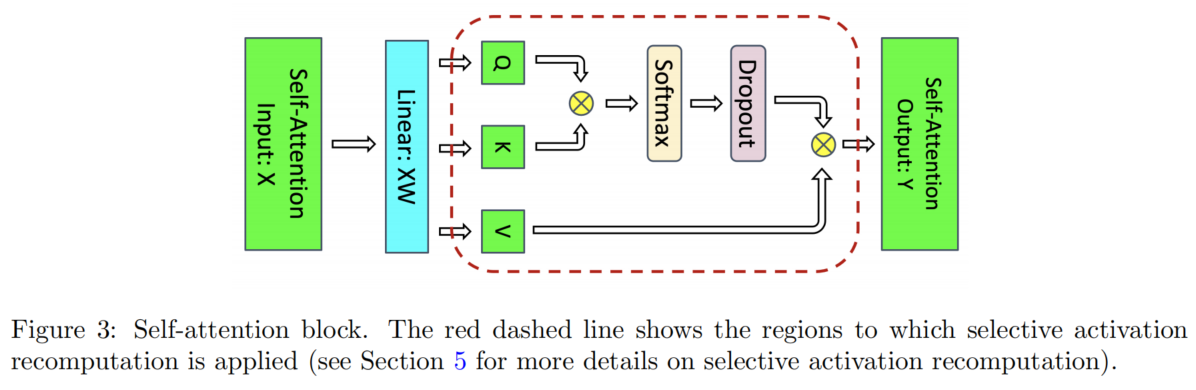
假设采用 FP16 / BF16 精度,下面我们对中间值的显存占用进行拆解分析。
Attention Block
| 中间值 | 大小 |
|---|---|
| Q/K/V projection 共享输入 | $2sbh$ |
| $QK^\top$ 需要存 Q 和 K | $4sbh$ |
| Softmax 输出 | $2as^2b$ |
| Softmax dropout mask | $as^2b$ |
| Attention over V: dropout 输出 | $2as^2b$ |
| Attention over V: V | $2sbh$ |
| Output linear projection 输入 | $2sbh$ |
| Attention dropout mask | $sbh$ |
中间值合计占用:
$$ \text{Attention} = 11sbh + 5as^2b $$
MLP Block
| 项 | 大小 |
|---|---|
| 第一个 linear 输入 | $2sbh$ |
| 第二个 linear 输入 | $8sbh$ |
| GeLU 输入 | $8sbh$ |
| MLP dropout mask | $sbh$ |
中间值合计占用:
$$ \text{MLP} = 11sbh + 5as^2b $$
LayerNorm
两个 LayerNorm,每个存输入 $2sbh$,所以
$$ \text{LayerNorms}=4sbh $$
合计
$$ \text{Total}=sbh(34+\frac{5as}{h}) $$
采用张量并行机制的 Transformer 架构
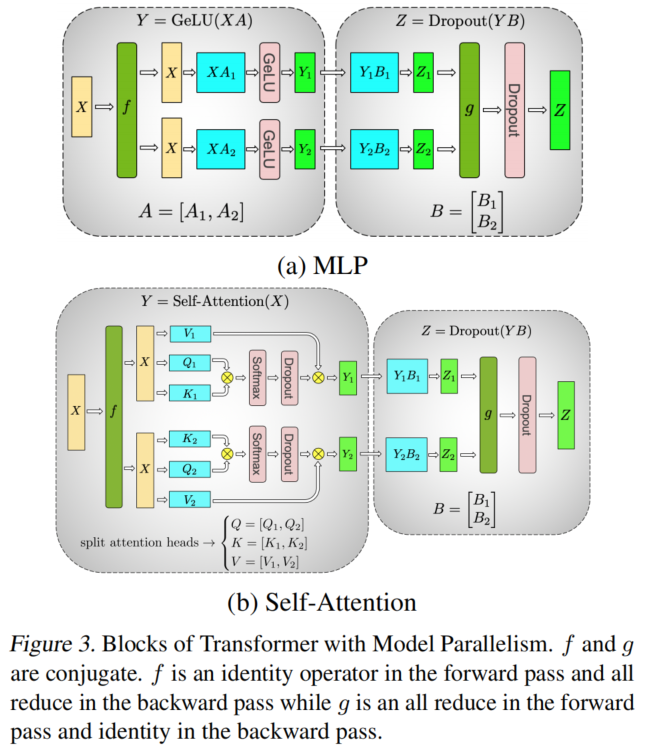
评论