软件调优(二):DataLoader
DataLoader
在深度学习中,往往处理大数据集时,一次将整个数据加载到内存中是不太现实的,比较好的方法就是将数据分批加载到内存中进行处理,这需要编写额外的代码来执行此操作。对此,pytorch 提供了一个 DataLoader 数据加载类帮我们做了这块工作:
from torch.utils.data import DataLoader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)简单描述一下以下几个重要参数:
dataset:必须首先使用数据集构造 DataLoader 类。batch_size: 批量加载的样本数。shuffle:每个 epoch 是否重新整理数据。sampler:指的是可选的 torch.utils.data.Sampler 类实例。采样器定义了检索样本的策略,顺序或随机或任何其他方式。使用采样器时应将 shuffle 设置为 false。batch_sampler:批处理级别。num_workers:加载数据所需的子进程数。collate_fn:将样本整理成批次。Torch 中可以进行自定义整理。pin_memory:拷贝数据到 CUDA Pinned Memory。persistent_workers:True代表一个 epoch 结束后不销毁 worker,下个 epoch 继续复用。只能在num_workers > 0时设置为True。
DataLoader 中 num_workers 参数的选择
workers 介绍
num_workers 是 torch.utils.data.DataLoader 的参数,用来控制加载数据时使用多少个子进程。
-
如果设置
num_workers = 0,DataLoader 不会启动额外的 worker 进程,此时数据加载和训练都在主进程中串行发生,流程类似:加载 batch 1 -> 训练 batch 1 -> 加载 batch 2 -> 训练 batch 2 -> 加载 batch 3 -> 训练 batch 3 -
如果设置
num_workers > 0,比如num_workers = 4时,DataLoader 会启动 4 个 worker 子进程。数据加载流程变成:
worker 提前加载 batch 2、3、4...
主进程训练 batch 1
训练完 batch 1 后,直接取已经准备好的 batch 2本质上,workers 提升性能的原因是减少 GPU 等待数据的时间。[1]
选择最佳 num_workers
使用 num-workers-bench.py 脚本测量最佳 num_workers 选择。
num-workers-bench.py
#!/usr/bin/env python
"""
这个基准测试用于观察 DataLoader 中 num_workers 参数对数据加载性能的影响。
通常情况下,num_workers > 0 时,DataLoader 会启用多个子进程并行加载数据,
从而减少主训练进程等待数据的时间,提升整体吞吐量。
用法:
./num-workers-bench.py
"""
import torch
import time
class MyDataset(torch.utils.data.Dataset):
def __init__(self):
# 创建一个大小约为 1 MB 的张量
self.tensor = torch.ones(1*2**18) # pytorch 中默认 torch.ones() 创建的是 float32(4字节)张量
def __len__(self):
return 1000
def __getitem__(self, idx):
# 模拟较慢的数据预处理过程
time.sleep(0.005)
return self.tensor
num_runs = 10
num_workers = 5
batch_size = 100
compute_emulation_time = 0.2
ds = MyDataset()
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
device = "cuda:0"
for num_workers in range(5):
dl = torch.utils.data.DataLoader(
ds,
batch_size=batch_size,
pin_memory=True,
num_workers=num_workers,
)
duration = 0
for i in range(num_runs):
slept_time = 0
start_event.record()
for batch in dl:
batch = batch.to(device=device, non_blocking=True)
# 模拟计算耗时,让 DataLoader worker 有时间提前准备下一批数据;
# 否则测试结果可能主要反映的是主进程等待 worker 加载数据的时间
time.sleep(compute_emulation_time)
# 后续会从总耗时中减去这段人为加入的计算延迟,
# 尽量单独衡量 DataLoader 迭代过程本身带来的开销
slept_time += compute_emulation_time
end_event.record()
torch.cuda.synchronize()
duration += start_event.elapsed_time(end_event) / 1000 - slept_time
duration /= num_runs
print(f"num_workers={num_workers}: average time: {duration:0.3f}")
输出示例:
pin_memory= True, non_blocking= True: average time: 0.459
pin_memory= True, non_blocking=False: average time: 0.522
pin_memory=False, non_blocking= True: average time: 0.658
pin_memory=False, non_blocking=False: average time: 0.646特别注意,num-workers-bench.py 在 docker 容器中运行容易出现类似的报错:
RuntimeError: unable to allocate shared memory(shm) for file </torch_826048_2310082876_0>: Resource temporarily unavailable (11)意思是 PyTorch DataLoader worker 进程想申请共享内存 /dev/shm,但是共享内存不够用了。
这是因为当 num_workers > 0 时,PyTorch 会启动 worker 子进程。worker 加载出的 tensor batch 需要传回主进程,这个过程通常会用到共享内存,也就是 /dev/shm。如果 /dev/shm
太小,就会出现你看到的错误。
在脚本的数据设置中,单个样本张量大小为 2^18 B = 1 MB,而 batch_size=100,所以一个 batch 大约 100 MB。而 DataLoader 在 num_workers>0 时,不只是准备当前 batch,还会预取后面的 batch,默认 prefetch_factor=2 也就是说,每个 worker 默认可能预取 2 个 batch。因此共享内存的压力大概可以估算为:
num_workers × prefetch_factor × batch_size × 单样本大小可以使用命令查看 /dev/shm 大小:
df -h /dev/shm解决方法是在 docker 容器启动时,增加 /dev/mem 大小:
# 方法一:固定为指定大小
docker run --shm-size=2g ...
# 方法二: 容器可以访问宿主机的全部共享内存区域
docker run --ipc=host ...DataLoader 中 pin_memory 和 non_blocking 参数的选择
pinned memory 介绍
默认情况下,主机端(CPU)分配的数据属于可分页内存(pageable memory)。GPU 无法直接访问这类内存。因此,当执行从可分页主机内存到设备内存的数据传输时,CUDA 驱动程序会先创建一个临时的固定内存缓冲区(pinned memory),将数据从可分页内存拷贝到该缓冲区中,之后 GPU 才能从固定内存中读取数据,如图中左侧所示。
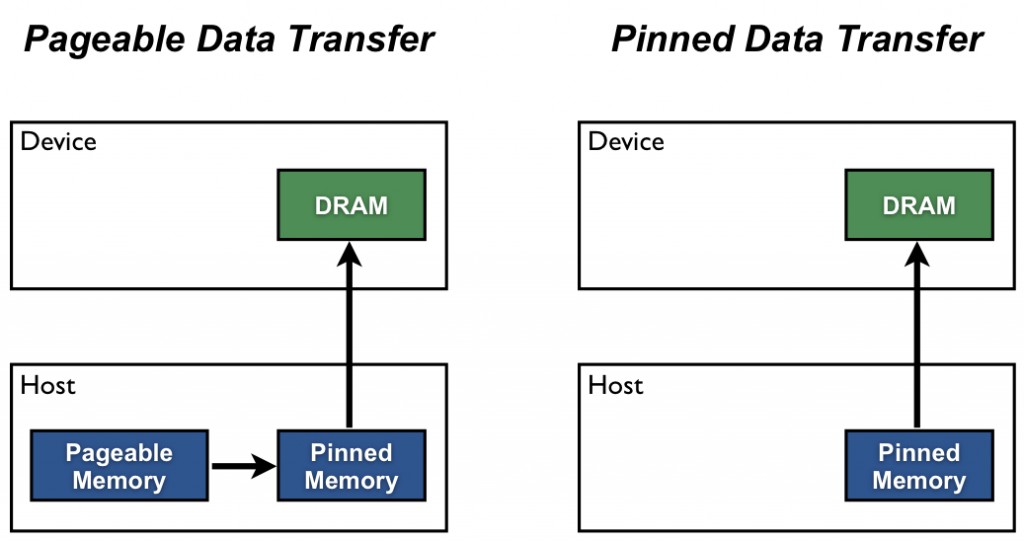
然而,CPU 执行从可分页内存到临时固定内存的拷贝会带来额外的时间开销,并且由于该缓冲区仅为临时使用,传输完成后便会被销毁。为了进一步提升数据传输效率,可以设置 pin_memory=True,其作用是:从一开始就将部分主机内存锁定为固定内存(如图中右侧所示),从而减少主机端内部的拷贝开销,避免额外的 CPU 内存复制时间[2]。
non_blocking 介绍
non_blocking 在 CPU/GPU 数据拷贝时尽量使用异步传输,减少 CPU 阻塞,并可能与 GPU 计算重叠。
常见用法:
batch = batch.to("cuda", non_blocking=True)选择最佳 pin_memory 和 non_blocking
脚本使用也有注意事项,参看此处。
pin-memory-non-block-bench.py
#!/usr/bin/env python
"""
这个基准测试用于观察以下两个设置组合对 CPU 到 GPU 数据传输性能的影响:
(1) DataLoader(pin_memory=True, ...)
(2) batch.to(device="cuda", non_blocking=True)
当使用页锁定内存,也就是 pinned memory,并配合 non_blocking=True 时,
CPU 到 GPU 的数据拷贝通常会更快,并且有机会与 GPU 计算过程发生重叠,
从而降低数据传输对整体训练流程的影响。
参考资料:
- https://pytorch.org/docs/stable/notes/cuda.html#use-pinned-memory-buffers
- https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
用法:
./pin-memory-non-block-bench.py
"""
import torch
import time
class MyDataset(torch.utils.data.Dataset):
def __init__(self):
# 创建一个大小约为 1 MB 的张量
self.tensor = torch.ones(1*2**18) # pytorch 中默认 torch.ones() 创建的是 float32(4字节)张量
def __len__(self):
return 1000
def __getitem__(self, idx):
return self.tensor
num_runs = 10
num_workers = 5
batch_size = 100
compute_emulation_time = 0.2
ds = MyDataset()
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
device = "cuda:0"
for pm in [True, False]:
for nb in [True, False]:
dl = torch.utils.data.DataLoader(
ds,
batch_size=batch_size,
pin_memory=pm,
num_workers=num_workers,
)
duration = 0
for i in range(num_runs):
slept_time = 0
start_event.record()
for batch in dl:
# 在使用 pinned memory 的基础上,non_blocking=True 可以进一步提升数据拷贝效率
batch = batch.to(device=device, non_blocking=nb)
# 模拟计算耗时,让 DataLoader worker 有时间提前准备下一批数据;
# 否则测试结果可能主要反映的是主进程等待 worker 加载数据的时间
time.sleep(compute_emulation_time)
# 后续会从总耗时中减去这段人为加入的计算延迟,
# 尽量单独衡量 DataLoader 迭代过程本身带来的开销
slept_time += compute_emulation_time
end_event.record()
torch.cuda.synchronize()
duration += start_event.elapsed_time(end_event) / 1000 - slept_time
duration /= num_runs
print(f"pin_memory={pm!s:>5}, non_blocking={nb!s:>5}: average time: {duration:0.3f}")
评论