Transformer 模型 GPU 显存分析(二):推理
整体架构
这幅图展示了 Decode-only Transformer 的总体架构图:
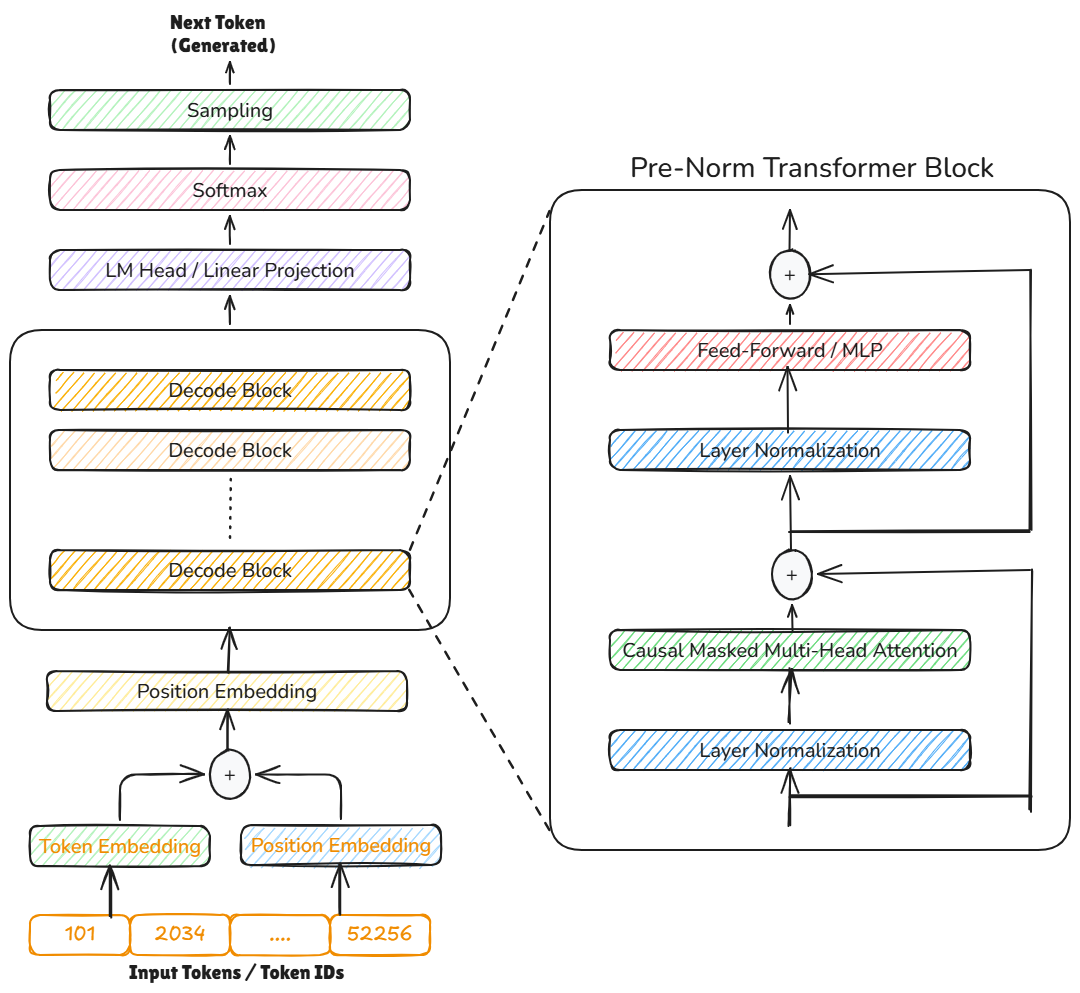
维度分析
B: batch sizeT: 当前输入序列长度L: Transformer 层数d_model: 隐藏层维度n_head: 注意力头数d_head: 每个注意力头的维度。d_head = d_model / n_head
Transformer-Block 中的维度
输入 x:
[B, T, d_model]
输出 out:
[B, T, d_model]
Attention 中的维度
输入 x:
[B, T, d_model]
经过线性层,得到Q, K, V:
Q = x @ WqK = x @ WkV = x @ Wv
如果是标准多头注意力 MHA,则
Q, K, V: [B, T, n_head, d_head]
一般会转置成:
Q, K, V: [B, n_head, T, d_head]
KV Cache 的维度
KV Cache 存的是每一层的历史 K 和 V。
对第 l 层:
k_cache[l], v_cache[l]: [B, n_head, T_cache, d_head]
其中,
T_cache是已经处理过的 token 数- 每一层都有自己的 K/V cache
- Q 不缓存,因为每一步只需要当前 token 的 Q
总 KV Cache 结构可以理解为:
KV Cache:
[
layer 0: K, V
layer 1: K, V
...
layer L-1: K, V
]Attention 在 Prefill 和 Decode 阶段的区别
Prefill 阶段
假设 prompt 长度是 T_prompt。
输入:
x: [B, T_prompt, d_model]
每层生成:
K, V: [B, n_head, T_prompt, d_head]
并写入 cache:
K_cache, V_cache: [B, n_head, T_prompt, d_head]
Attention 计算:
-
scores = Q @ K^T
维度:
-
Q: [B, n_head, T_prompt, d_head] K^T: [B, n_head, d_head, T_prompt] scores: [B, n_head, T_prompt, T_prompt]
输出:
-
attn_out: [B, n_head, T_prompt, d_head] 合并 heads 后: [B, T_prompt, d_model]
Decode 阶段
每次只输入一个新 token:
x_new: [B, 1, d_model]
当前 token 生成:
Q_new, K_new, V_new: [B, n_head, 1, d_head]
把新的 K/V 追加到 cache:
K_cache, v_cache : [B, n_head, T_cache + 1, d_head]
Attention 使用 Q_new 和完整的 K_cache/V_cache 做注意力,计算维度:
Q_new: [B, n_head, 1, d_head]
K_cache: [B, n_head, T_cache + 1, d_head]
scores = Q_new @ K_cache^T
scores: [B, n_head, 1, T_cache + 1]再乘以 V:
V_cache: [B, n_head, T_cache + 1, d_head]
attn_out: [B, n_head, 1, d_head]合并 heads:
attn_out: [B, 1, d_model]MLP 层维度
Attention 输出后进入 MLP。
输入:
[B, T, d_model]
常见 FFN 维度:
- up projection: [B, T, d_model] → [B, T, d_ff]
- activation
- down projection: [B, T, d_ff] → [B, T, d_model]通常:
d_ff = 4 × d_model
最后输出 logits
最后一层输出:
hidden: [B, T, d_model]
经过 LM Head:
logits = hidden @ W_vocab
其中:
W_vocab: [d_model, vocab_size]
输出:
logits: [B, T, vocab_size]
Decode 阶段只关心最后一个位置:
logits: [B, 1, vocab_size]
然后采样得到下一个 token。
FLOPs 分析
Attention 的 Prefill 阶段
Prefill 一次性处理 T_p 个 prompt, 每层 transformer-block FLOPs 近似为:
FLOPs = (QKV 投影 + attn_out 计算 + Feed-Forward 计算)
下面展开了各个部分的计算,先给个结论,Attention 的 Prefill 阶段的
QKV 投影
其中,QKV 投影计算为:
- Q = x @ Wq
- K = x @ Wk
- V = x @ Wv其中各自维度:
- x: [B, T_p, d_model]
- Wq, Wk, Qv: [d_model, n_head, d_head]故 QKV 投影的 [2]
attn_out 计算
attn_out 计算包括两部分:
- 计算 scores (此处省略了一些计算)[3]
- 计算 atte_out
其中各自维度:
Q: [B, n_head, T_p, d_head]
K^T: [B, n_head, d_head, T_p]
scores: [B, n_head, T_p, T_p]
V: [B, n_head, d_head, T_p]故 atte-out 计算的
Feed-Forward 计算
如果是普通 Feed-Forward 计算, 各自的维度:
- up projection: [B, T_p, d_model] → [B, T_p, d_ff]
- down projection: [B, T_p, d_ff] → [B, T_p, d_model]
- 其中d_ff = 4 * d_model故普通 Feed-Forward 计算的
Attention 的 Decode 阶段
Decode 阶段与 Prefill 阶段有两个不同:
- Decode 阶段 每次只处理 1 个新 token。
- Decode 阶段 使用 KV Cache,我们假设 KV Cache的长度均为
相应可得 Attention 的 Decode 阶段的
LM Head FLOPs
最后 hidden 映射到词表:
[B, 1, d_model] × [d_model, vocab_size] → [B, 1, vocab_size]
每个生成 token 的 LM Head 的
生成 N 个 token,则 LM Head 的
如果 vocab 很大,比如 32k、50k,这部分也不小。
显存分析
推理时的显存主要由两部分组成:
模型权重
模型参数量为 ,单个浮点数所占字节为,则权重显存:
对于FP16 / BF16格式,b = 2 bytes。
KV Cache
对于 MQA, 每层存:
K_cache: [B, n_head, T_c, d_head]
V_cache: [B, n_head, T_c, d_head]由于 d_model = n_head - d_head,所以每层 KV cache 元素数:
对于所有层:
如果是 FP16/BF16:
激活显存
推理时不需要保存反向传播激活,所以激活显存通常较小。
评论